
The amount of data being generated by businesses is snowballing; in fact, the International Data Corporation claims that, by 2025, globally produced data will exceed 175 zettabytes. Being able to process these huge amounts of data and analyze them in real-time quickly is becoming critical for any business that wants to stay competitive. Managing, analyzing, and utilizing such data effectively requires data engineering services. A well-designed data pipeline architecture provides a framework to handle these large data volumes and to process them in a way that makes the data usable and actionable, completely changing the modern business landscape.
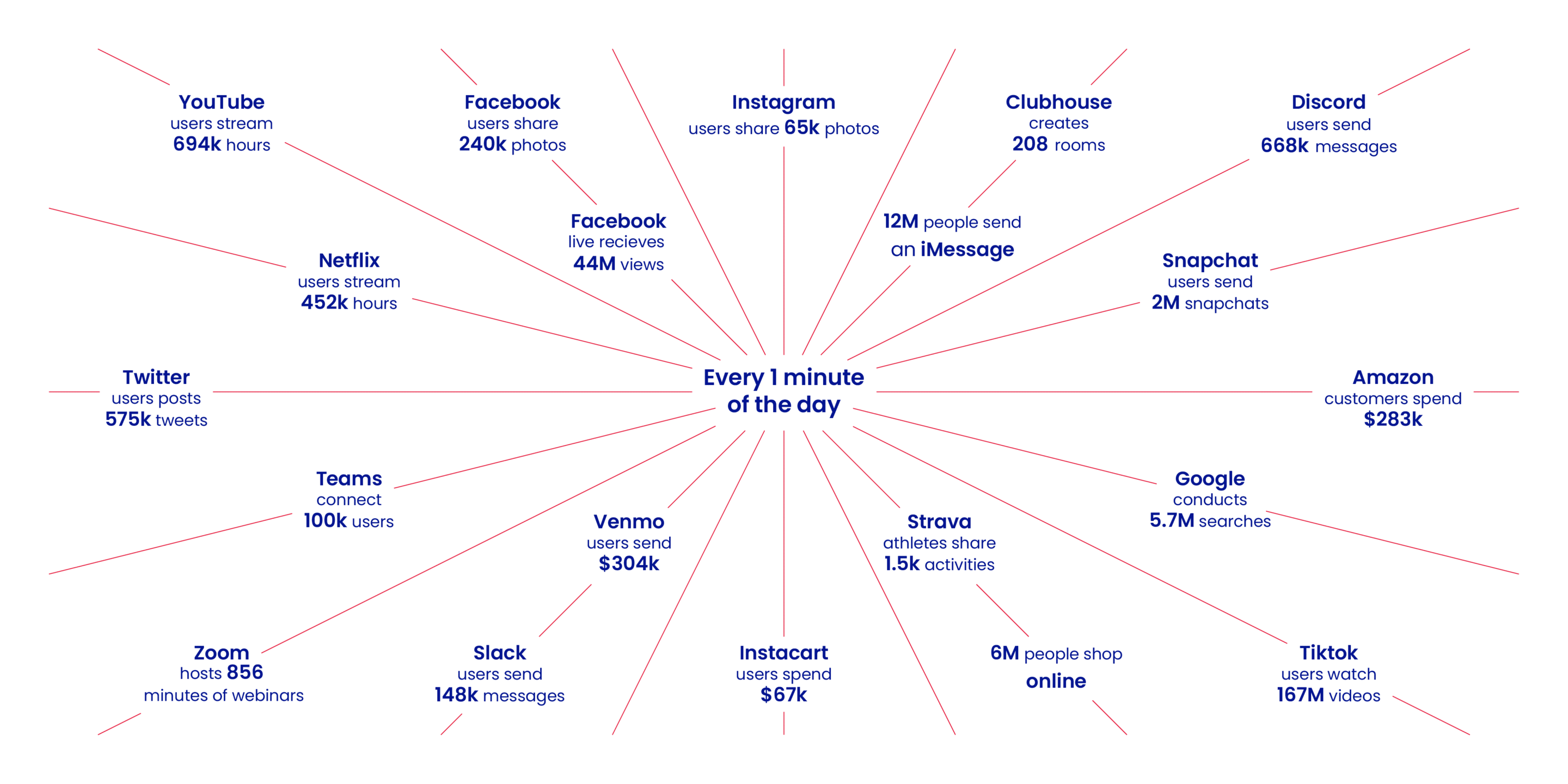
What is a data pipeline, and what does it mean for your business?
Let’s start with a small vocabulary connected to data usage in business:
Data — any information: audio, video, text, or digits.
Data acquisition — loading data from sources (e.g., sensors, applications, devices) into the pipeline.
Data transformation — transforming unstructured data into structured data or vice versa, or transforming one type of structured data into another type of structured data (e.g., from JSON to XML).
Data cleaning — removing duplicates and other noisy information from the dataset.
Data enrichment — adding information to the dataset (e.g., adding addresses to a contact information database).
Data aggregation — grouping records together so that one can perform an analysis on aggregated groups rather than individual records (e.g., calculating average sales by city).
Data storage — storing datasets in a way that allows them to be accessed later or shared with others who might be interested (e.g., saving results in a database or sending them out over email).
A data pipeline is a series of processes and workflows that move data from one system or application to another for processing, storing, and/or analyzing.
In simple terms, a data pipeline is a system or architecture that allows you to move data from its source to a destination while performing various operations on the data along the way. This may involve extracting data from a database, transforming the data into a different format, cleaning the data, and loading the data into another database or data storage system.
Data pipeline stages
A data pipeline is the sequence of stages and processes used to collect, process, and analyze data. Typically, data pipelines consist of the following steps:
- Data Collection: The first stage of a data pipeline is collecting data from various sources. This can include transactional systems, log files, external sources (such as sensor platforms, smartphones, web applications, or robots), and more.
- Data Extraction, Transformation, and Loading (ETL pipeline): Once the data is collected, it must be cleaned, transformed, and loaded into a storage system. This process is known as ETL, which involves extracting the relevant data, transforming it into a format that can be used for analysis, and loading it into a storage system such as a data warehouse or data lake.
- Data Storage: The cleaned and transformed data is then stored in a data warehouse or data lake, allowing for access and analysis by business intelligence tools.
- Data Analysis: The stored data can then be analyzed using various tools and techniques to gain insights and inform data-driven decisions.
- Data Management: Finally, the pipeline includes data management, which ensures that the data is accurate, complete, and up-to-date. This includes:
- Metadata collection
- Statistics generated for monitoring systems
- Data integrity monitoring
- Monitoring changes in the data
Each step can be enhanced with artificial intelligence and machine learning separately or simultaneously; however, making the system work requires professional data engineers.
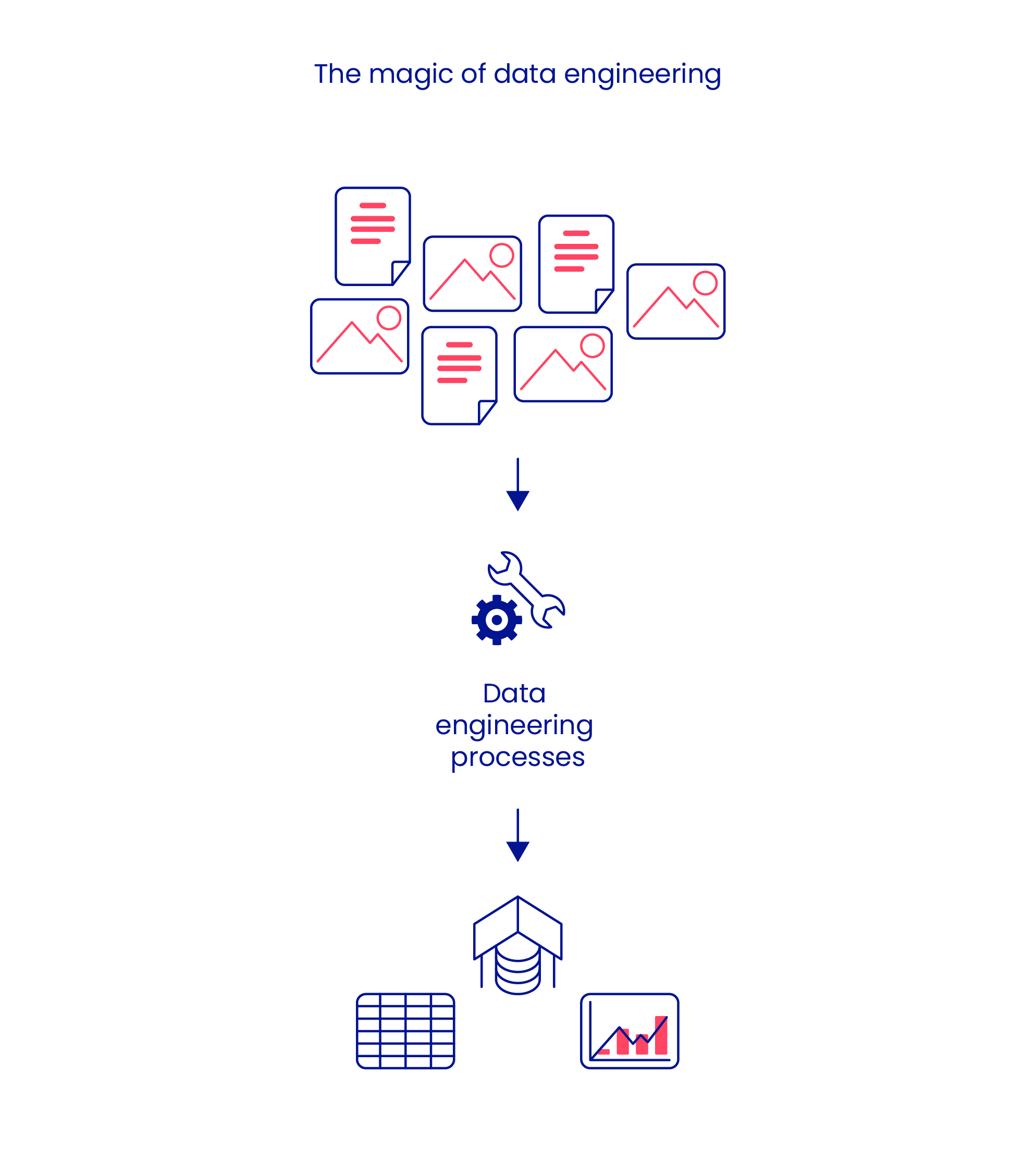
Why contemporary businesses should thoughtfully develop a data pipeline architecture
- First, modern data pipelines can help businesses collect, process, and analyze vast amounts of data in a more efficient and automated way. This can enable companies to gain insights and make data-driven decisions more quickly and effectively.
- Second, a well-made data pipeline architecture ensures the quality and integrity of data, as people can control how data flows through the different stages of the pipeline. This is important for businesses that rely on accurate and reliable data to make decisions and drive their operations.
- Third, having a data pipeline business can improve security and compliance. Data pipelines can be designed to include security measures such as encryption or access controls at various stages, making it more difficult for unauthorized individuals to access sensitive data. It can also ensure that data is being handled and processed in compliance with relevant regulations and industry standards.
- Finally, a well-designed data pipeline can be easily adapted to accommodate new data sources and analysis requirements, allowing companies to respond quickly to new opportunities and challenges.
Data pipelines are the backbone of modern IT. Practically every application, website, and technology will involve data pipelines at some point. However, deciding on an architecture and executing one is far from easy. Many different approaches, different use cases, and different technologies can be applied.
Benefits of a data pipeline
A data pipeline offers a business several benefits, including:
- Automation of data processing: Data pipelines automate (hence, speed up) the collection, cleaning, transformation, and analysis of data, saving time and reducing the potential for errors.
- Improved efficiency: By automating data processing, a well-designed pipeline improves the efficiency of data-related tasks, allowing businesses to make better use of their resources.
- Increased data accuracy: Data pipelines ensure that data is processed consistently, making the data neat and improving the insights that can be derived from it.
- Greater scalability: Data pipelines can handle large amounts of data and can be easily scaled to accommodate growing data needs.
- Better decision-making: Data pipelines provide businesses with the information they need to make better decisions, which can help them to stay competitive and increase their chances of success.
- Real-time processing: A data pipeline allows real-time processing and analysis, which can help businesses quickly identify and respond to trends or issues as they arise.
Overall, data pipelines can help a business manage, analyze and utilize data effectively, and make better data-driven decisions, which can ultimately lead to increased revenue and growth.
Data warehousing & data lake explained
To store and manage vast amounts of data, businesses can utilize two approaches data warehousing and data lakes.
A data warehouse is a centralized storage specifically designed for storing and managing large amounts of structured data from multiple sources that have been cleaned, transformed, and organized in a way that makes it easy to analyze. Such data is typically organized with an explicit schema and defined relationships between the data. With just business intelligence tools, this structure makes the query and analysis of the data convenient. It’s like a library where all the books are arranged neatly on shelves, and you can easily find the information you need.
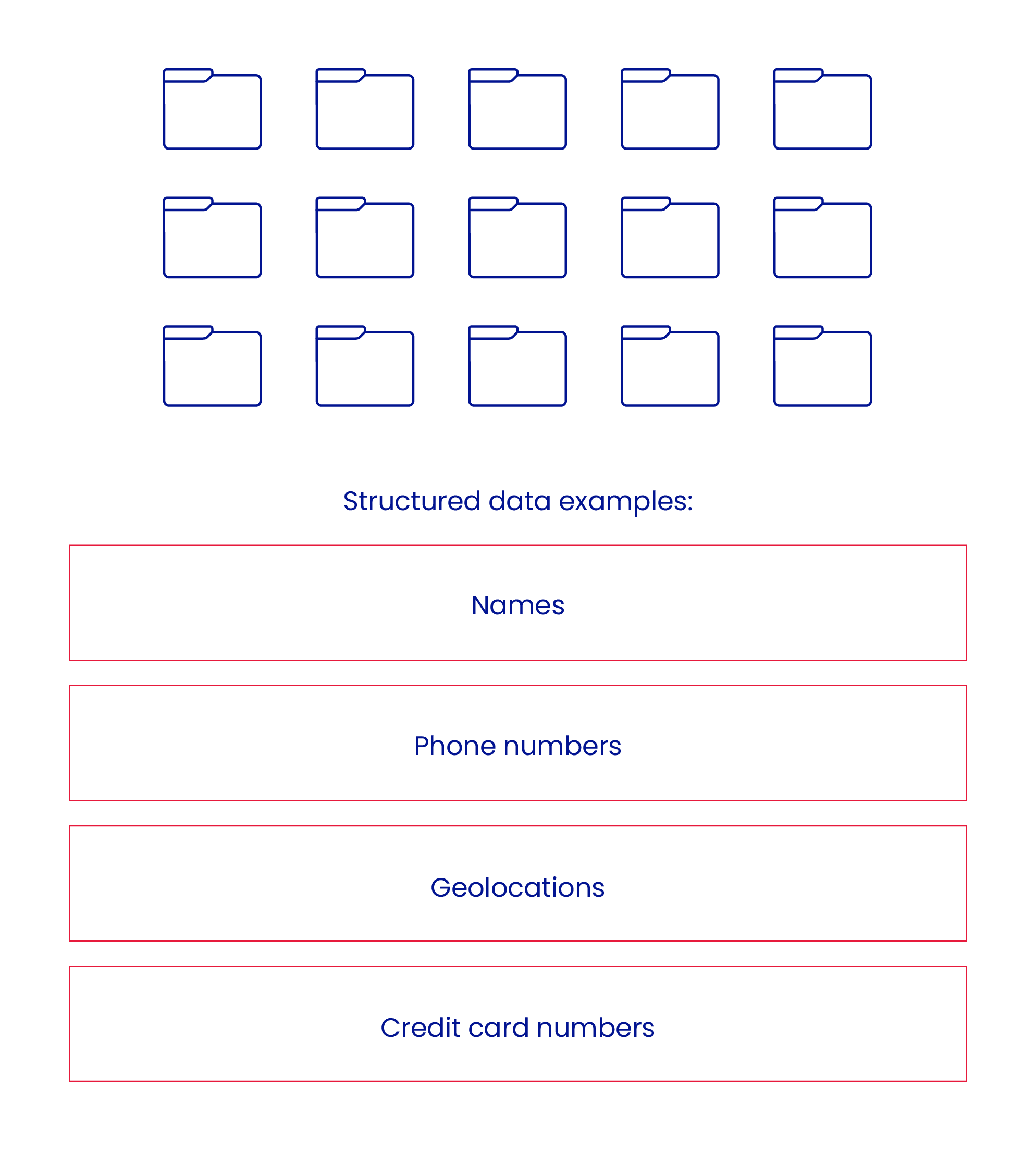
Hence, data warehousing is the best solution for scenarios where the data have to be stored and structured. For example, a retail company may use one to store and analyze customer info collected from various data sources, such as online sales, in-store transactions, and customer feedback. This data can be integrated into a centralized data warehouse, where it can be analyzed to gain insights into customer behavior and preferences.
In contrast, a data lake is a more flexible approach to data storing and managing. A data lake usually stores raw data, which can be structured, semi-structured, unstructured, or binary. Imagine it as a big, messy storeroom where everything is thrown in without much organization or, as the name suggests, it’s like a lake where you can go fishing for data, but you might have to sift through a lot of information to find what you’re looking for. Nonetheless, it is a good option for centralized storage of all types of raw and unstructured data, including data from different sources and formats. This makes it fairly simple to collect data, as it’s not necessary to standardize and format all incoming data, which would be complex and very time-consuming.
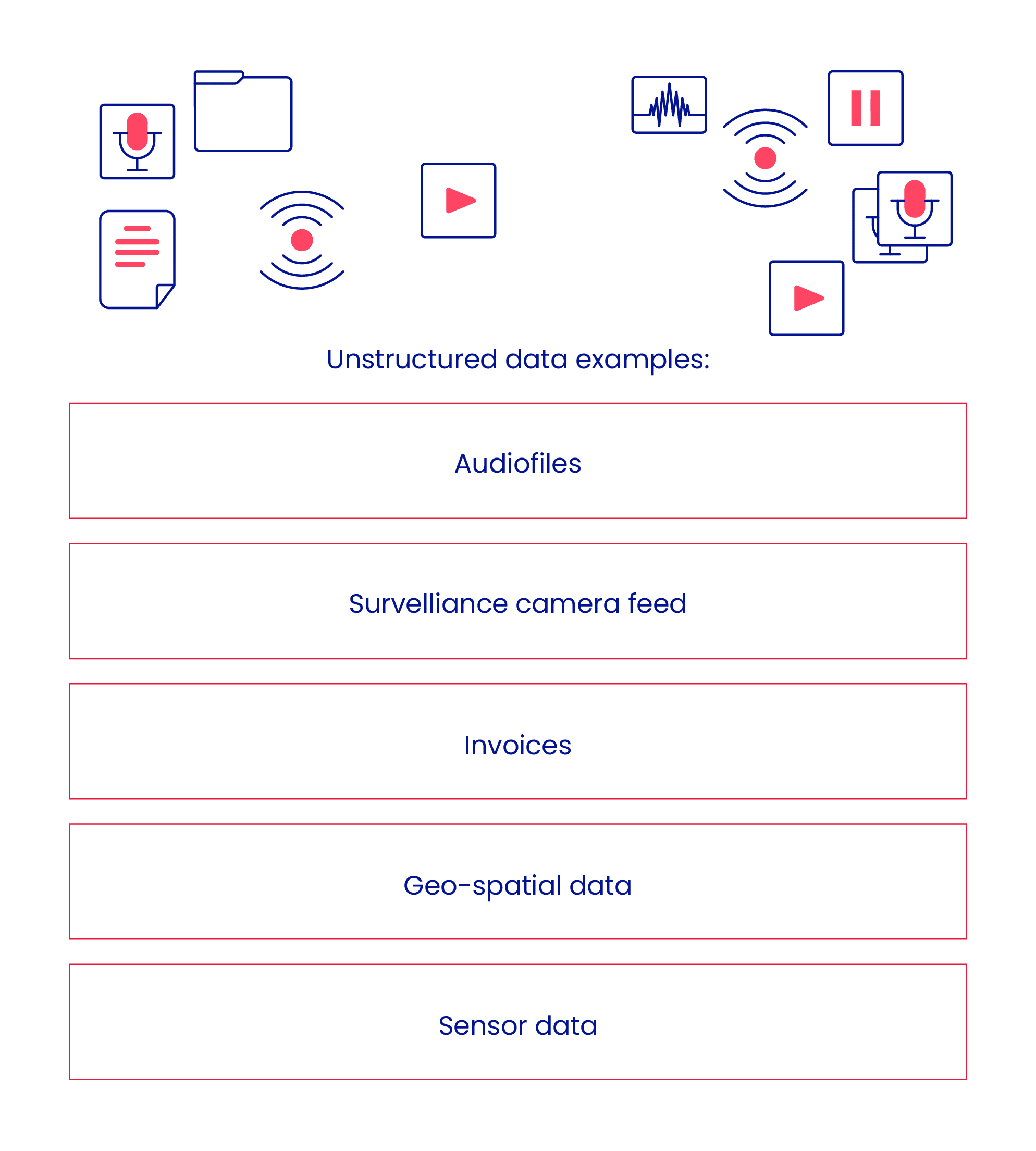
However, the flexibility of data lakes also makes them dangerous for obvious reasons – poorly managed data lakes turn into swamps, as people lose track of what’s where, where the data came from, and what it means. It’s common for data lakes to serve as sources for data pipelines that take the data, transform it as required, and make it available for end users in an easier-to-use environment.
Data lakes are suitable for scenarios where the data coming in is varied. There’s a lot of it, and you don’t want to make assumptions about how it should be processed – retaining raw data makes it possible to come back to it when it turns out that the assumptions made in a specific analysis do not hold. For example, a healthcare organization might collect data on patient health records, clinical trial results, MRI or X-ray scans, and insurance claims from various sources. Then, the company can use machine learning to identify patterns and trends in patient health, optimize treatment plans, and identify new treatment options.
The impact on your business
Both data warehousing and data lakes can have a significant impact on a business. A data warehouse can support a centralized and structured approach to storing and managing data, making it easier to perform complex queries and analyses. In contrast, a data lake can offer a more flexible approach to storing and managing data, allowing businesses to maintain large amounts of data from various sources. It’s actually a common pattern to use both in a single organization, depending on the use case.
Additionally, an emerging concept that is seeing more and more activity is the data lakehouse: the structure and performance of data warehouses combined with the flexibility of a data lake. However, it is still a developing concept, so consult data engineering experts before adopting it.
To sum up, data warehousing is best suited for businesses that require a high level of structure and organization for their data and need to perform complex queries and analyses. Contrarily, a data lake is best suited for businesses that need to store and process large amounts of different types of data but don’t require a high level of structure or organization.
Automated data pipelines vs. data pipelines with manual steps/human intervention
Businesses can either choose fully automated data pipelines or maintain some manual steps in any data-management or -processing procedure.
An automated data pipeline is designed to collect, process, and analyze data without the need for manual intervention. To achieve this goal, specialized software and programmed tools perform data extraction, transformation, and loading (ETL). Automated pipelines are typically more efficient and can handle larger amounts of data more quickly and accurately.
Manual steps in a data pipeline, on the other hand, imply human intervention in collecting, processing, and analyzing data. Such tasks can include manually extracting data from various sources, cleaning and preparing the data for analysis, and manually performing analyses. While manual steps provide more flexibility and adaptability to changing requirements, they are also more time-consuming and can be prone to errors.
Here are some benefits of fully automated data pipelines:
- Efficiency: Automated pipelines can handle large amounts of data more quickly and accurately, reducing the resources required for data processing.
- Scalability: Automated pipelines can quickly scale to handle increasing amounts of data, making them suitable for businesses that are growing or expecting to grow.
- Consistency: Automated pipelines are less prone to human error, providing more accurate and consistent data quality.
- Cost-effective: Automated pipelines can save time and resources compared to manual pipelines, making them more cost-effective in the long run.
- Monitoring: Automated pipelines can be set up to monitor the processing of data, making it easier to troubleshoot and resolve problems that may occur.
On the other hand, data pipelines with manual steps can offer the following benefits:
- Flexibility: Manual actions can be more flexible and adaptable to changing requirements, as they allow for more human intervention and decision-making.
- Control: Manual actions can give a business a sense of more control over data processing, allowing users to make adjustments as needed.
- Understanding: Humans can make sense of the data in a way automated pipelines may not be able to.
- Customization: Manual steps can be easily customized to meet the business’s specific needs.
- Low-tech requirements: Manual steps don’t require expensive software or specialized expertise, making it accessible to businesses with limited resources.
Ultimately, the choice between fully automated data pipelines and ones with manual steps will depend on the specific needs of the business and its available resources. Automated pipelines are typically more efficient and can handle large amounts of data quickly and accurately, but manual pipelines can be more flexible and adaptable to changing requirements.
Data pipeline: In-house vs. outsourced
Unfortunately, you can’t buy a ready-made pipeline. All pipelines, by their nature, have to be developed from scratch and are tailored to the use case. While there are shortcuts in the sense that the platform you use – e.g., Snowflake, AWS, Teradata – provides some tools and abstractions that make developing the pipeline easier, it’s still all custom work.
Having an in-house team for data engineering might look fancy, but, in fact, the workload is uneven. The experts will have much more responsibility at the beginning of the project, and, after it is launched, the workload will decrease iteratively.
Building a data pipeline from scratch in-house can provide the following benefits:
- Customization: A custom-built pipeline can be tailored to the specific needs of the business, which can help to ensure that the pipeline is fully integrated with existing systems and processes.
- Control: Building a pipeline in-house allows a business to have complete control over the pipeline and its development, which can be helpful when dealing with sensitive data.
- Flexibility: Building a data pipeline in-house allows a business to make changes to the pipeline as needed, providing more flexibility to adapt to new requirements.
On the other hand, through working with an outsourced team, a custom data pipeline can provide the same features alongside the following additional benefits:
- Cost-effective: Building a pipeline with an outsourced team can be more cost-effective than building one from scratch in-house, as, for example, the development costs do not include social charges.
- Time-saving: Creating a data pipeline with a team of experts can save a business a significant amount of time as the team already has experience in data pipeline building, configuration, and integration with the existing systems.
- Support and maintenance: Outsourced experts will gladly provide ongoing support and maintenance of a data pipeline they created for a relatively small price. Thus, businesses can resolve issues without the expertise to maintain a pipeline alone or with the extra expenditures in hiring in-house specialists.
- Features and capabilities: Outsourced companies usually are ready for a broader range of challenges in data pipeline building, having different, sometimes highly specialized, experts. Thus, they can work on a broader range of features and capabilities that may not be available when building a pipeline in-house.
Ultimately, the decision of whether to build or buy a data pipeline should be based on a careful assessment of the specific needs of the business, the available resources and expertise, and the cost-benefit analysis.
Conclusion: Best practices for optimizing your data pipeline architecture
A thoroughly built data pipeline is vital for contemporary businesses because it allows them to efficiently and effectively collect, process, and analyze vast amounts of data. This enables them to make more informed decisions, improve operations, and gain a competitive advantage. Additionally, a data pipeline ensures data integrity and security and allows for easy scaling and maintenance of data systems. Overall, a well-designed data pipeline architecture is essential for businesses that rely on data for decision-making and want to remain competitive in today’s data-driven marketplace.
To achieve the best results in building data pipeline architecture, try to follow these recommendations:
- Choose the correct data storage layer – the nature of your data and the current and likely future use cases will dictate how and where your data should be stored. The wrong choice will likely make any future data migrations a headache.
- Choose your platform well – different platforms and tools provide varying functionalities. If the tool of your choice is not able to support all your use cases, you’ll end up with multiple tools, which makes maintenance and monitoring more complex. This is especially important if you choose a proprietary tool with a vendor lock-in.
- Especially true in the case of big data, there are many factors that influence the final performance and usability of the pipelines. If you feel you lack in-house expertise, consult a professional, or you may find yourself building the whole thing at least twice.