This article discusses how to make your business processes more efficient with human-in-the-loop machine learning. In addition to helping you find suitable applications and revealing how to start with these, this guide is for anyone wanting to bring machine learning into their business.
What is Machine Learning and what is its connection with business?
Machine learning (ML) is often pitched as an amazing solution to a lot of problems. Yes, ML is pretty much the closest thing we have to magic, it has a lot of business benefits and it can solve many problems or at least improve many situations. However, as Gartner has predicted, 85% of AI projects fail. Thus, there are obviously some skills required to tame this magic. One of these skills is understanding how to make your business work with machine learning.
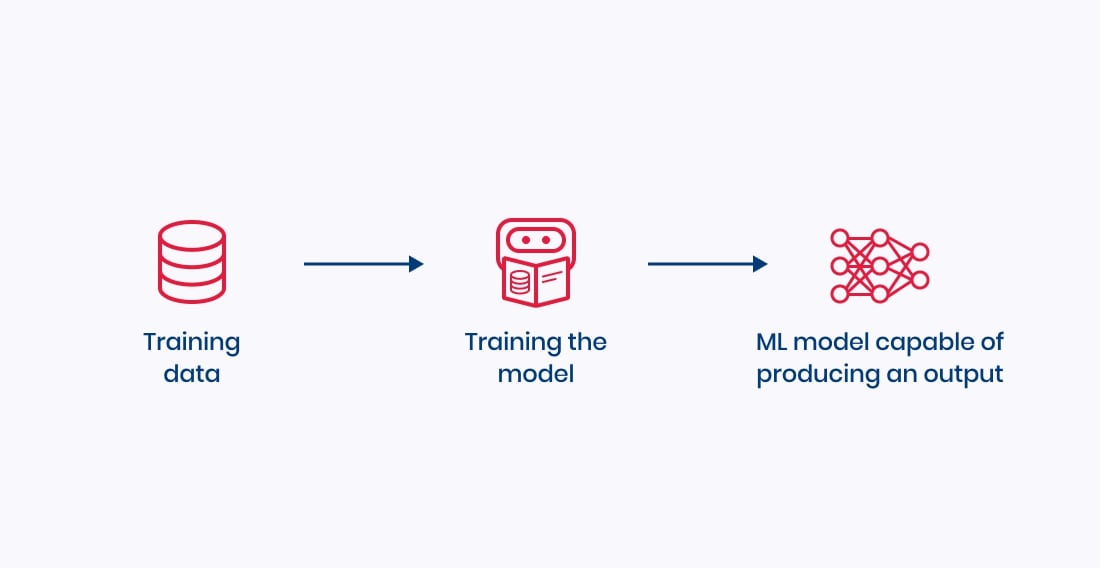
So what is machine learning?Luckily, a business person doesn’t need to worry about how difficult the technical definition of machine learning is and just remember the following process as shown in Figure 1. The machine needs training data to learn from, a machine learning expert creates a process where some magic happens, and, finally, we get a machine learning (ML) model that is able to produce output from input. Almost like a production line.
Figure 1. The simplified process of creating a machine learning model
For those who want more: Machine learning takes input (e.g. information from your CRM, databases, spreadsheets) and produces an output (e.g. finding fraudsters, handling claims, classifying what the customer asked). A machine learns from sample data how to produce the required output. For most businesses, that’s it, and there is no need to delve deeper. Just talk to your ML partner for specifics as needed.
How to identify a machine learning use case?
Machine learning cannot solve the problem if the problem statement is my business is not profitable, which is sad, but let’s try to stay positive. We have to find out the right process for ML. First, try to answer the following questions:
Does the design of a problem you are trying to solve look like a process?
Is there a clear beginning and an end with logical steps in between?
If it is an existing process, is there somebody who could show how it is done at the moment?
How are the decisions made and what kind of data is being used to make those decisions?
If you answer these questions and find that there is a process and it is done more or less in a similar way (even complex things might be solved following clear rules), then there is repetition and routine; consequently, there is a good chance that you have found a process that can be (semi-)automated with machine learning.
Nonetheless, just because you can automate something with machine learning does not mean that you should.
There might be easier ways, and there might not be a positive ROI and other issues, but this is not within the scope of this article. Let’s focus on the scenario where everybody gives this project the green light.
What does a suitable business process look like?
As said above, the process should have a clear beginning and an end with logical steps in between. The beginning could be somebody or some system looking at a set of input data (e.g. incoming messages, claims, declarations) at certain times, either regularly or when the data comes in. The logical steps in between could be, for example, somebody looking at an input (e.g. customer message) and making a decision based on that (Figure 2).
Figure 2. An auditor making a decision based on input
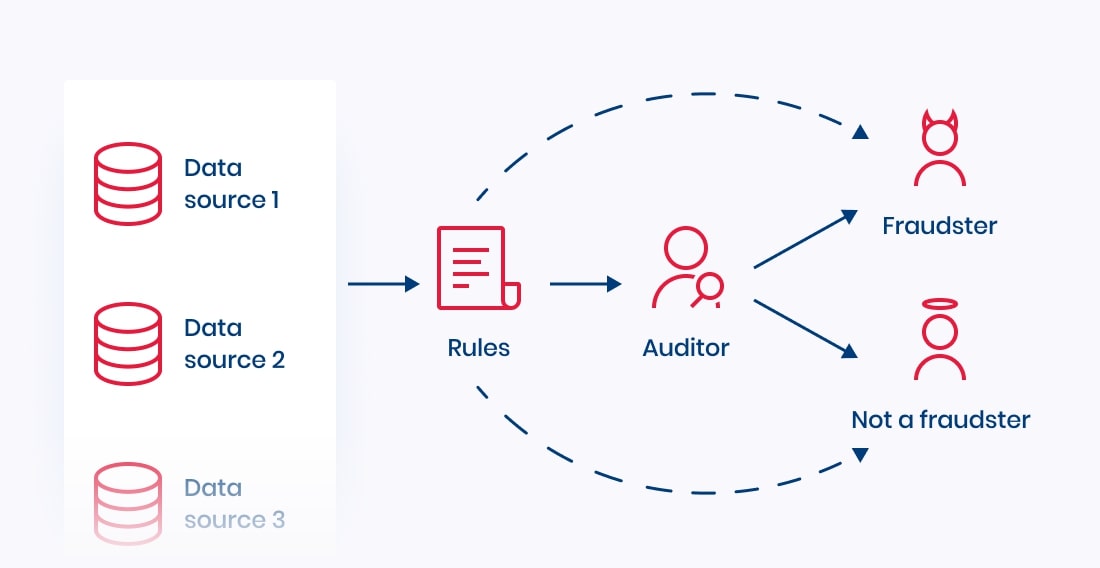
There might also be rules which help a human to make the decision (Figure 3) or in some cases even automate it. If the process can be automated well with a few rules, machine learning is not necessary.
In contrast, if there are a lot of data sources, it is not realistic to come up with all the rules, as this might make you too dependent on experts to write these rules (leaving you vulnerable should they leave the company for one reason or another). Moreover, maintaining such rules is often a nightmare. Thus, in such cases, it’s probably a good idea to bring in machine learning.
Figure 3. An auditor making a decision with the help of rules
Last but not least, the output should be something clear. In the examples shown on Figure 2 and Figure 3, the issue is whether somebody is a fraudster or not. Because the machine should learn from the clearest possible examples, precision is key. You should review the process – possibly with your ML partner – and decide whether the examples that are given to the machine to learn from are as standardized and clear as possible. For example, you might consider replacing a free-form text box with a dropdown menu to make it clear.
As stated above, both processes might be suitable for human-in-the-loop machine learning, yet the devil is in the details. Ensure that they are suitable processes for AI automation by discussing it both with the business side and your ML partner. Remember, machine learning can automate a lot of different processes and deal with various data sources from database fields and free form text to images and speech data. With this and much more, you can be bold when discussing solutions with your ML partner.
How does a machine learn and what should you keep in mind?
Making a machine learn is often very difficult. Fortunately, a business person doesn’t need to keep it in mind and just remember the following process as shown in Figure 1: training data together with some magic turns it into an ML model which generates output from an input.
Yet, there is a lot that a business should know about the challenges of creating, developing and maintaining the machine learning model. From the business side, we should keep an eye on at least the following:
What points to keep in mind when dealing with an AI project?
As machine learning models use examples and the world is often very complex, a simple rule is “the more, the better”. Of course, this might be easier said than done (for example, it might not be realistic with rare diseases), so you should decide on a data-collection protocol that is neither too costly nor time-consuming.
Nonetheless, in many cases, there are easy wins in remaking a data-collection process or streamlining it, especially with a human-in-the-loop system where you just need to make sure that you are collecting/recording the activities of human experts to learn from their decisions.
Machine learning model output often has a “confidence” level. With high confidence, you can use machine learning as an automated process (if the business rules/risks allow it). With an output with low confidence, we should let a human review it. This way the process is efficient and you minimize the number of mistakes.
Whether with only people or together with machines, getting better should always be a goal for every organization. Together with machines, it is slightly easier. The easiest cases can probably be automated relatively quickly. Usually, the more complicated a case, the more input examples are needed. Thankfully, the previous point helps with this. Since humans are handling cases that are more complicated for the machine, they are also generating training data for the machines to learn from.
Human and machine intelligence working together
Putting the two worlds together is not complicated. First, you need to bring an ML model into the process. Secondly, you need to create a loop that generates training data for the model to learn from. Yes, there are multiple variations of making it happen, but, in essence, that’s it.
So let’s look at a few examples of how we can automate the process from Figures 2 and 3 discussed earlier. In all of these examples, the machine learning model is trained on historical data – from which the machine can figure out how to produce output based on different input examples.
Example 1 in Figure 4. This figure represents the most efficient loop, but it might not always be applicable because of regulations or risk averseness.
First, the machine learning model processes the input data and produces an output based on it.
If the confidence level of that output is high, then the fully automated decision goes further.
If the confidence level is not high enough, then the auditor will review the case, give human feedback, and then provide a decision.
By manually adding the reviewed cases to the training examples, data scientists improve machine learning algorithms; consequently, the machine becomes more efficient over time with more complicated examples. In theory, it might be possible to reach full automation with this machine learning process. However, life is often so complex that new edge cases requiring human revision keep popping up.
Example 2 in Figure 5.In some cases, as mentioned above, due to regulations or risk averseness, a human should execute quality control and review every decision made by machine intelligence.
In this system, the ML model can produce an output for every case; it can contain a decision, a confidence level, and, in many cases, the most influential factor that shaped the decision.
The auditors or other specialists involved can accept or reject the output proposed by the model.
Even though a human needs to review every case, the speedup might still be significant because of the considerably reduced investigative work. The human-made decisions are then added to the system as labeled data to improve the accuracy of AI-given suggestions.
Examples 3 in Figure 6. This figure represents cases with limited automation possibilities because of regulations or risk averseness, where human intelligence is needed. The difference is the number of cases.
Sometimes there are so many that human feedback is possible only for a handful. And let’s be realistic: in the real world, we only deal with a handful of fraudsters (at least in a well-functioning society).
So the machine learning model prioritizes the cases and the auditors focus on the highest of these priorities. As above, the human decision will supplement the machine learning data.
Again, such prioritization boosts productivity by reducing the time spent on cases requiring human oversight. Important note: pay some attention to new types of aberrations. For this, auditors should review a random sample and/or anomalous case from time to time, but this technical detail can be overcome.
This symbiosis is beneficial for both sides. From the business side, the processes get (semi-)automated, mistakes are reduced, and people get to focus on more challenging work. The ML model does not get bored, does not require vacation or even lunch. The processes become more reliable, predictable and efficient. From the machine learning side, the system will gain a reliable source of training data which helps it to make fewer mistakes and become better over time. The result is a cycle that reinforces itself over time as shown in Figure 7.
Figure 7. Reinforcing the cycle of human in the loop of machine learning systems
How to start?
We provide a simple checklist of four steps for you: here it is.
Check if a business process is suitable for a machine learning application (check out more in the section What does a suitable business process look like?).
The partner should truly know what machine learning is and how it should be implemented into real-life business processes. By all means, the best machine learning partner should understand and be sincerely interested in your business goals.
The partner should research and then explain to you whether the entire machine learning process is convenient from the technical perspective and identify all prerequisites needed for implementation.
Last but not the least, your ML partner should understand the amount of work required because some cases may need a pilot algorithm or data research.
Once you have approval from the technical and business sides, you need to put together a team suitable for this type of project and get going.
Words of caution:
Unless you have a well-functioning ML team in-house, do not consider hiring data scientists.
Data science is not “regular IT”.
You need a lot of skill sets, the work is unevenly distributed, and most probably, once the projects are finished, you won’t have enough work for a whole machine learning team or sometimes even a single data scientist.
If you want to get results year after year, allow a reliable partner to deliver them.
Conclusion
Machine learning can automate processes with a clear beginning and an end with logical steps in between. ML needs data to learn from and a human in the loop can create reliable training data of high quality. If done correctly, a loop will reinforce itself improving over time.
As a loop system with human intelligence involved can be arranged in multiple ways, please, talk to your ML partner to understand the specifics.
On that note, why not have MindTitan as that partner?