
AI forecasts emergency calls for Estonian police
March 31st, 2022

Back in 2018, the International Data Corporation predicted that the total amount of data produced globally would exceed 175 zettabytes by 2025. Statista has made similar predictions. This massive volume of data must have some purpose to serve. Otherwise, nobody would be keeping track of these numbers.
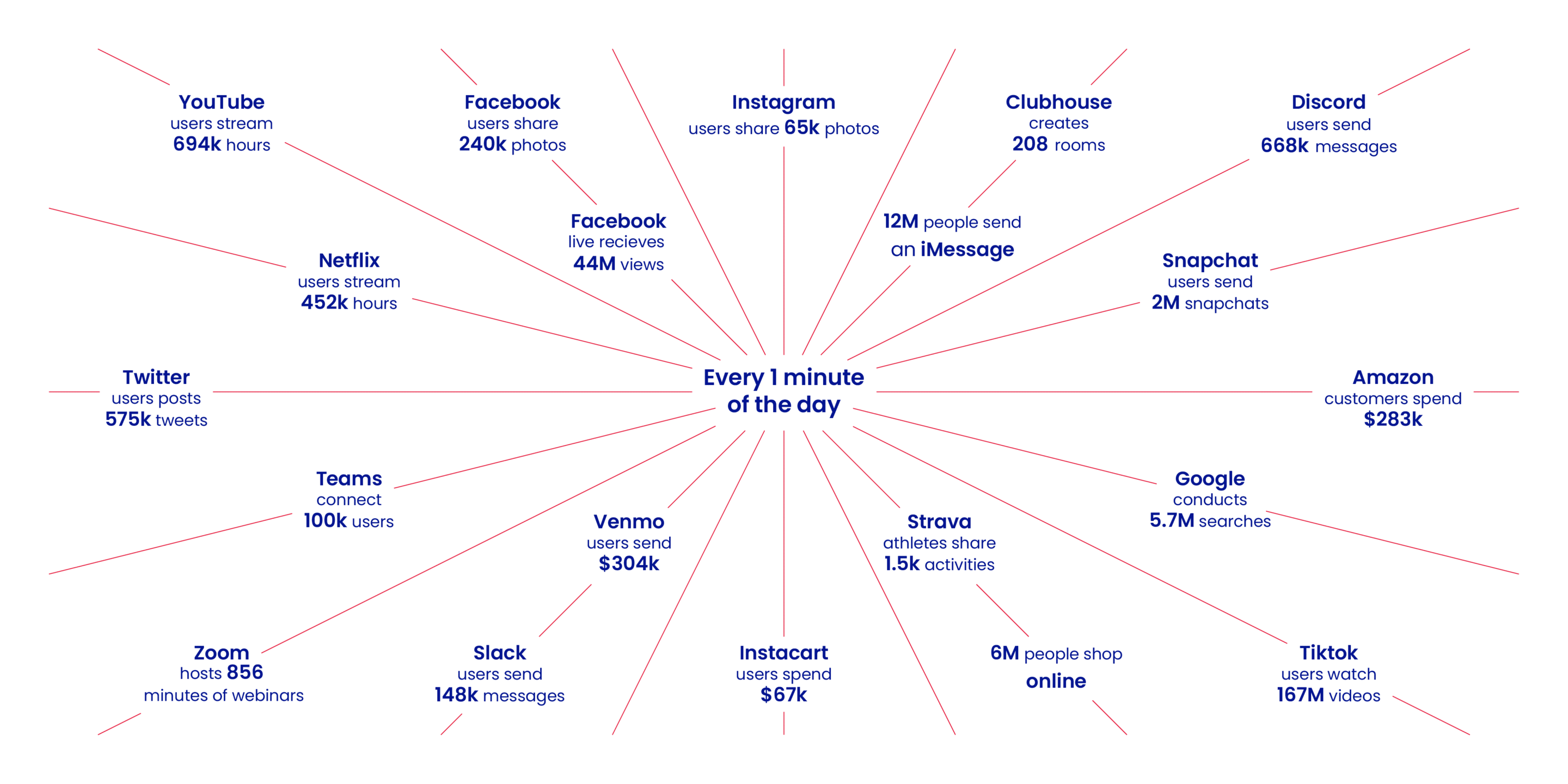
The tons of data that we produce every minute of every day is of great importance to organizations of all types. Businesses gather valuable insights from these data and use them to streamline internal processes and provide improved services to consumers, among other things. However, randomly collected raw data itself might as well be gibberish.
The findings from a recent Research and Markets report indicate that businesses are expected to allocate a sizable portion of their resources and budgets in search of experts who can help them make sense of the different types of data that they collect from one or more sources. Organizations do not want their data projects to fail.
Before we talk about how and why data engineering services are becoming increasingly important for organizations of all sizes and industries, allow us to shed some light on what data engineering is. In this discussion, we will cover the following:
Data engineering refers to the process of data management, involving the setting up of certain mechanisms to aid data collection and storage. It provides a sense of structure to all the data that a business intends to collect and utilize to its benefit. The process of data engineering helps to convert haphazard, meaningless data into organized information.
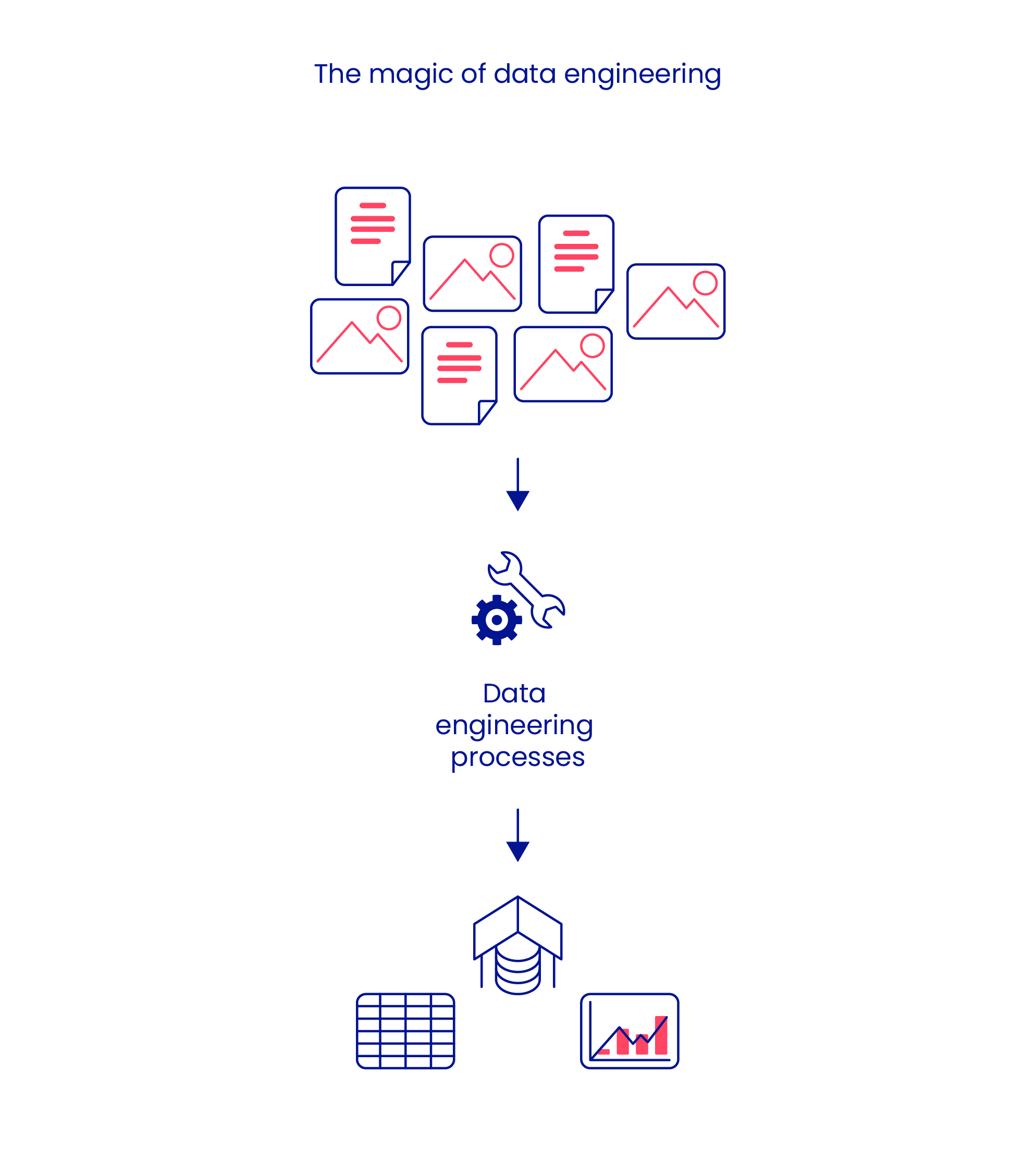
Data engineering is the key to holistic business process management.
From finance and accounting to sales and customer support, a wide range of business functions relies heavily on data.
Data engineering makes it possible for businesses to extract important information from large datasets and make key decisions after careful data analysis.
The demand for data engineering services has skyrocketed over the past few years as the world has embraced big data.
Volume
Velocity
Variety
These can help you identify whether the data you are dealing with can be classified as big data. If you collect data in large amounts that are produced over short periods and have a wide range of types, classes, labels, and/or formats, then you have a big data problem on your hands.
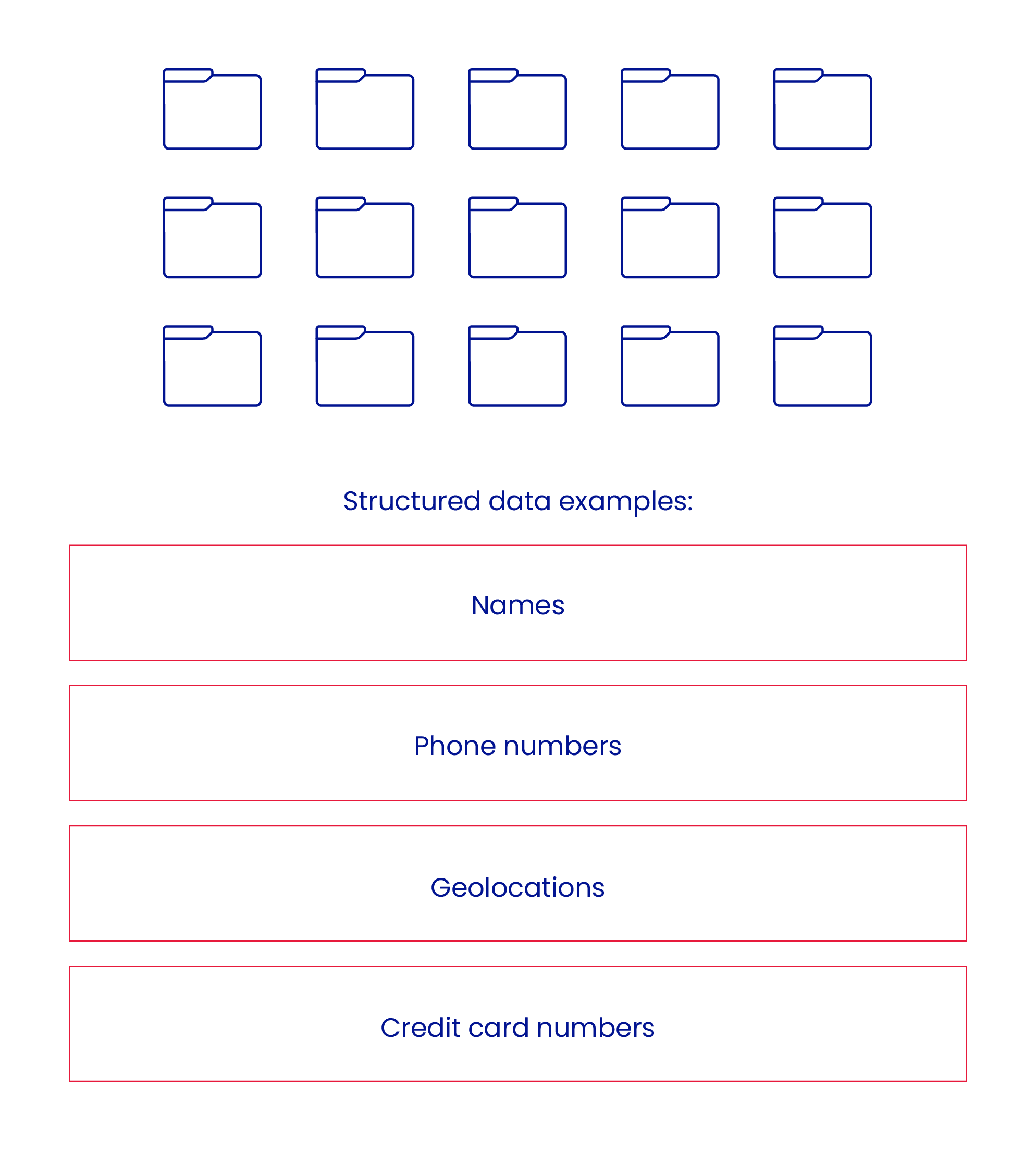
Structured data is strictly relational.
That means it can be conveniently stored in a relational database management system (RDBMS).
A traditional database stores data in row-column format with distinct identifiers, characteristics, and relationships established between one or more tables.
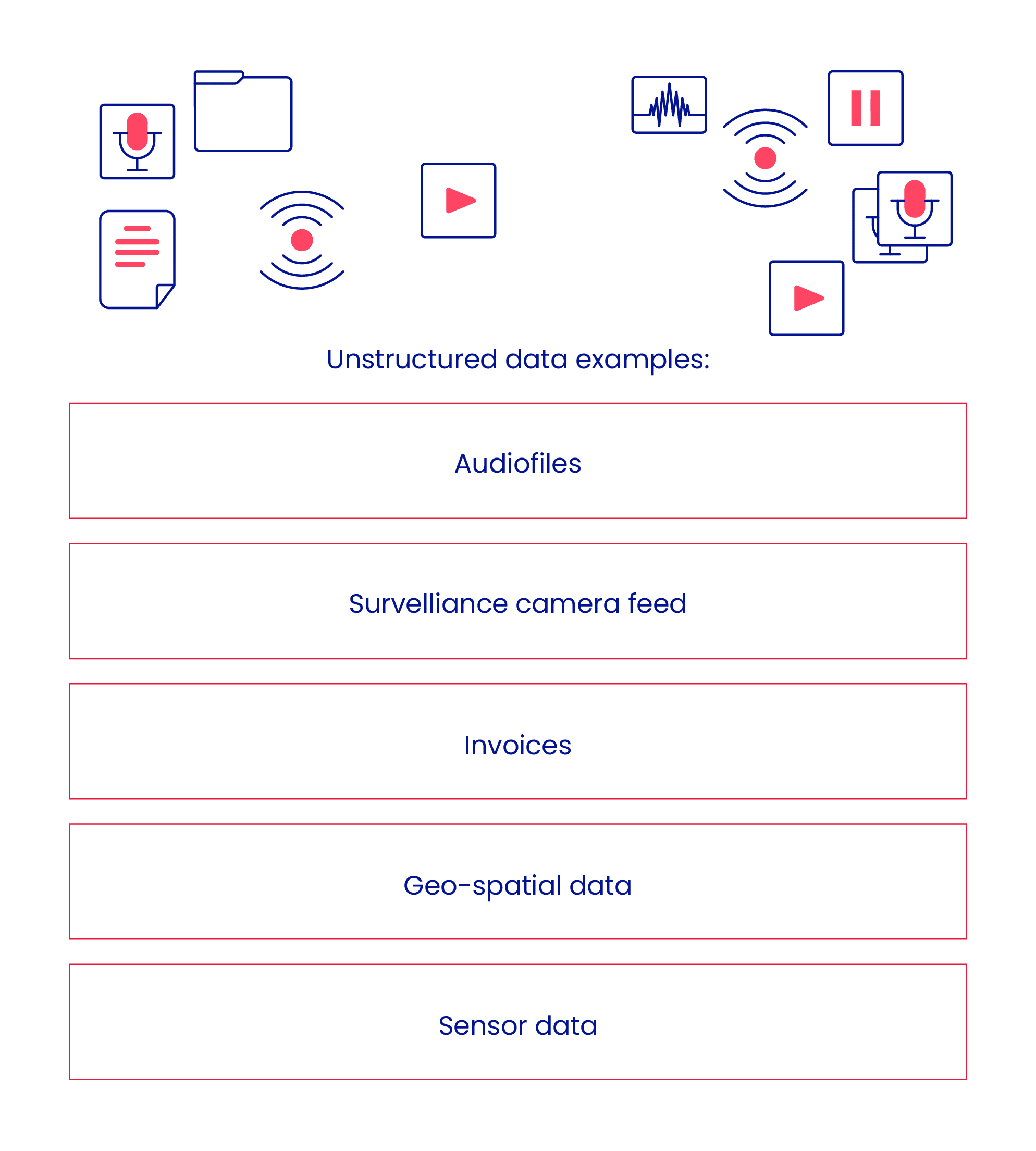
You might face significant trouble trying to store unstructured data – often in the form of text, audio, video, image, or other files – in an RDBMS.
For example, it can be logically difficult, inefficient, and/or expensive to store data from your Fitbit or live surveillance data in a table made of rows and columns.
This is where non-relational or “NoSQL” databases come into play.
In the case of images, videos and similar, you rarely keep them in a database but store the metadata and file reference in the database, while the actual content is stored in a file system or object storage.

Semi-structured data falls somewhere between relational and non-relational data – it can be a combination of both.
Therefore, it needs to be stored in a non-relational database. Semi-structured data has some sort of structure but does not adhere to a fixed schema or data model.
It may contain metadata that helps organize it but it is not suitable for storage in a tabular format.
The people who are tasked with handling raw data and architecting its storage, infrastructure, and flow mechanisms are called data engineers. They are responsible for constructing and managing data pipelines, databases, data warehouses, and/or data lakes.
A data pipeline defines the mechanism that determines the flow of data from its origin to its destination, including the various processes or transformations that the data might undergo along the way. A standard pipeline is quite like one of the most basic computing processes of Input → Processing → Output. It comprises three basic parts that are:
The source or origin
Transference and/or processing mechanisms
The destination
The source refers to the starting point of the data flow cycle, that is, the location where the data enters the pipeline. There are many types of data sources, such as relational and non-relational databases. They can collect many types of data, ranging from simple text-based answers obtained through a simple form on a website to sensor data collected from an IoT device e.g., smart home devices such as lightbulbs, air quality sensors, and thermostats.
When dealing with big data, traditional databases such as MS Access, MySQL, or other relational database management systems (DBMS) might not be capable of handling such large volumes, velocities, and varieties of data. Thus, organizations turn to larger, more flexible data stores that are specially built to handle big data. Some examples of this type of data store are d distributed file systems (e.g. HDFS), object storage, or databases that are specifically designed to handle big data (e.g. MongoDB, Kafka, Druid).
In a typical data pipeline, the second part of the pipeline is where the collected data transforms. Often, this type of pipeline is called an ETL data pipeline (Extract – Transform – Load). In this phase, the data collected from one or more sources undergoes some sort of processing to make it more useful and digestible.
There are two common methods to process data in big data engineering:

In batch processing, data is processed in batches of varying sizes. If the batches are very small – for example, only a couple of samples – it is called mini batching, but the batches can also be days’ worth of data.

In contrast, stream processing revolves around processing data as it comes in, on the level of single samples. The system does not wait for the periodic build-up of a backlog. Instead, the processing happens in real-time. Big data engineering often incorporates a mix of batch and stream processing – Lambda architecture – as there can be multiple use cases to cater to.
Where the data ends up after being processed is referred to as its destination. Just like the data source, the destination in a particular pipeline can also be of many types. Some pipelines are built to fetch data from various sources and process it to remove inconsistencies and organize it. This pipeline in particular might end up storing the refined data in another data store, such as a relational database. Another pipeline might be tasked with supplying processed data to a database that supplies data to a dashboard. Thus, the destination depends on the purpose for which the relayed or transformed data is to be used.
Many people often confuse data engineers and data scientists. In recent times, we have even seen a bit of overlap between the two roles. However, there are some basic differences.
Data engineering, as we discussed before, pertains to handling raw data and setting up a suitable architecture to aid with refining or processing that data. Data engineers may have to think about things like how long the data needs to be stored, or which platform or type of data store would be best for the job. Their responsibilities also include the first round of data cleaning, checking for and fixing errors, and organizing the data to make it more presentable and easier to understand.
Data science, on the other hand, has more to do with the analytical part of data processing. Data scientists are one of the many end-users that ultimately utilize the data that is cleaned, processed, and supplied by the data engineers. They may run machine learning algorithms, complex statistical processes, or other analytical procedures to extract important insights from the data and use them for critical business decision-making.
Let us talk about the slightly more technical aspect of data engineering.
Some specific tools and technologies are used by many data engineers that empower them to work their magic. Below, we mention some of the most popular programming languages, databases, data warehouse solutions, and other big data technologies that are used for data engineering projects.

To enable communication between different systems (whether they are data storage or ETL processes), you need computer algorithms. Therefore, data engineers need to be skilled in certain programming languages.
The primary languages used by data engineers are SQL, Python, Java, and Scala. However, other languages (such as R, Julia, or Rust) are also used in some companies for performing certain tasks.
These are the two broad categories of databases often used in data engineering projects. When the data to be stored is structured in nature, it can easily be stored in a relational database.
For semi- or unstructured data, businesses use non-relational or NoSQL databases.
There can be multiple databases of different types involved in a single project depending on the organization’s storage, processing, and/or data modeling needs.
If you are dealing with a big data engineering problem or even just an extensive disk-based database that requires real-time operations, it is crucial to keep latency to a minimum.
For this purpose, certain caching systems need to be put in place. In-memory databases quicken the process to query data by eliminating disk I/O.
There are several pre-built data warehousing platforms available on the market today, ready for corporations to use.
Most of these data solutions are well-equipped to meet a business’s big data engineering needs.
To make data engineering processes faster and more efficient, data engineers often use workflow scheduling and automation tools for better data pipeline management.
With a scheduler, you can save time by automating repetitive tasks, save resources by eliminating redundant processes, easily modify the dataflow, and log each event as your data flows through the pipeline.
Some other notable data engineering tools and technologies are listed below. These include file systems, object stores, pipeline construction platforms, querying services, big data analytics, and visualization platforms, business intelligence tools, and data integration tools: Apache Hadoop; Amazon S3 (Simple Storage Service); Apache Spark; Apache Kafka; Amazon Athena; dbt; Tableau; Power BI; Talend Open Studio; Informatica; Kubernetes; Kubeflow.
To make the best use of all available tools and technologies, it is vital to follow certain data engineering practices that will gain maximal returns for the business. Let’s talk about six of the top industry practices that set apart a good professional data engineer from an amazing one.
The data engineering field is still relatively new and undergoing many rapid developments every day. Thus, it can be hard to stay on top of all these advancements. The good news is that a lot of newer big data tools are built to work using methods already familiar to any data engineer.
Instead of investing in learning a brand-new technology or framework from scratch, you can go for tools that are based on traditional concepts. This will not only save precious resources that would otherwise be spent on extensive training but also prevent you from incurring losses in the form of project delays.
Here is an example from our project for Elisa, for which we conducted network log analysis using Google BigQuery. Under the hood, BigQuery works on a distributed file system with a query engine that manages the distribution of workloads on the nodes holding the data. For the end-user, though, it is just another dialect of SQL, enabling any engineer to work on this big data project.
Due to the intricate and immensely interrelated nature of most data engineering systems, it is important to ensure that any dependencies are taken care of.
There are two solutions to this problem. The first one involves spending time and effort manually establishing connections between various systems. The easier, resource-efficient solution involves using tools that have built-in connectivity features.
This is a major reason why we extensively use Apache Airflow to manage data pipelines. Airflow features numerous operators and connectors that allow you to easily manage credentials for connections to various sources. Furthermore, it also covers a lot of the boilerplate code that big data engineers might otherwise need to write just to access data sources and sinks.

Most transformations and procedures that must be conducted on data can be managed with most tools. It does happen, though, that some other tool or language is either needed or just more efficient or easy to implement to fit your need. To be ready for this highly likely scenario, you shouldn’t expect your chosen platform or tool set to handle every possible situation but keep some flexibility in the system by using easily extendable tools.
Almost all data pipelines written at MindTitan include a lot of machine learning functionality. As ML-driven algorithms can be quite varied in terms of the tools that they need, our pipeline orchestration tools need to be very nonrestrictive when it comes to what technologies can be used to execute the various steps in the pipeline. This is another reason why we extensively use Apache Airflow and, on occasion, Kubeflow.
What is data engineering without proper documentation? Your big data project can quickly turn into a big mess.
When handling such large volumes of data, it can be very easy to lose track of what is going on. Proper documentation helps preserve critical information about what data is where, how it should be interpreted, and what fields should be used to join it with other data sources. Maintaining event logs ensures that all changes, no matter how minute or seemingly insignificant, are tracked. Documentation also helps with error detection, tracking, monitoring, and executing appropriate corrective measures.

Proper documentation helps not just the current data team(s) but also those that come after. Businesses might end up switching out platforms, tools, or entire engineering teams at any point in time. To introduce new technologies or teams, it is vital to understand the existing system, which cannot be done if there is no written record of all the happenings within the pipeline.
Many businesses tend to rely heavily on batch processing as opposed to streaming. However, one needs to keep in mind the various drawbacks that batch processing can have. For use cases where it is required to process data in real-time, a longer than necessary delay can incur heavy losses or reduce profit margins significantly.
One option to tackle this problem is to switch your data models completely to streaming. However, if you cannot afford to make such a drastic change, you can go for a hybrid model. Another shortcut is to simulate streaming by reducing the intervals set for your batch processes to minimize latency.
For the fault monitoring system that we set up at Elisa, many processes occur at the same time. There is a constant flow of incoming calls on various topics, and it is vital to be notified of issues as early as possible. At Elisa, we use machine learning to classify calls into various categories, including issue reports on specific services. These data are fed to Kafka, which the anomaly detection system uses to detect potential issues and report them to the technical team in real-time.
As we discussed in the previous point, there is almost always a need for multiple processes to run within a single pipeline. Without proper control mechanisms, this can quickly lead to deadlocks or blocks. To avoid processes from hogging or competing for shared resources, it is important to establish concurrency within the data pipeline.

Consider our Elisa network log analysis module. The data is loaded into BigQuery, which is a distributed data processing tool that scales automatically to fit the load. The data engineers use it to run periodic machine learning workloads predicting customer experience index, and the data analysts run ad-hoc data analysis jobs as they come along.
For the near future, the data engineering team is most excited about the wider adoption of low-maintenance and easy-to-use data stack. A lot has been achieved, despite some tools being partially in development or lacking the polish that would make them “easy to use”





