
As we advance further into the era of big data, it has become crucial for businesses to understand the difference between data engineering services and data science. While both fields play a pivotal role in the modern data landscape, their responsibilities, skill sets, and impacts on businesses differ significantly.
In this comprehensive guide, we’ll delve into the worlds of data science and data engineering, offering valuable insights for businesspeople to better grasp their critical roles in today’s data-driven economy. From the daily tasks and expertise required for each position to the unique contributions they make to modern industries, we’ll provide an in-depth comparison to help you navigate the complex and dynamic data realm. To solve these issues, businesspeople need to know the problem space for data science and machine learning to know whom to ask and what to ask, expressing themselves in domain terms.
Entering the data world: data engineering and data science
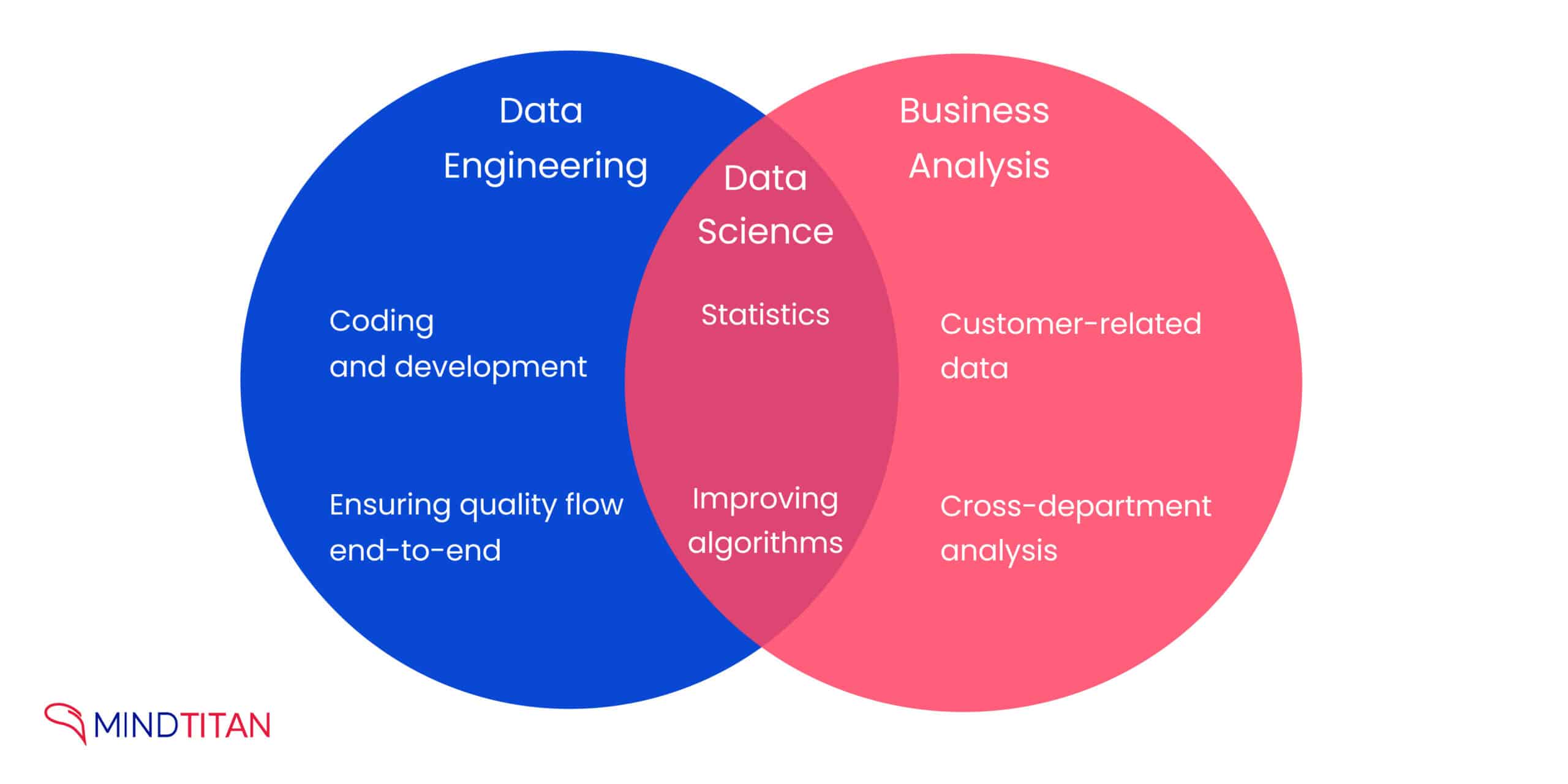
The realms of data engineering and data science have taken center stage in transforming raw, complex data into valuable, actionable insights. These two interconnected fields form the backbone of the data world. Data science employs a combination of statistics, algorithms, and machine learning (ML) techniques to interpret, understand, and provide foresight from complex data sets. In contrast, data engineering provides a foundation by designing, constructing, and maintaining data architecture, databases, and processing systems, enabling the smooth and efficient management of large amounts of data. Together, these disciplines empower businesses to make informed decisions, optimize operations, and ultimately drive growth and innovation.
Data science: a window into data-driven insights
Data science (DS) is a potent blend of mathematics, statistics, specialized programming, advanced analytics, artificial intelligence (AI), and machine learning, fortified with domain-specific knowledge. The resulting elixir reveals hidden, actionable insights within an organization’s data, shaping decision-making and strategic planning.
With the proliferation of data sources and the consequent data avalanche, DS has emerged as one of the fastest-expanding fields across all industries. It’s hardly surprising, then, that the Harvard Business Review crowned data scientist as the “sexiest job of the 21st century“. Organizations are growing increasingly reliant on data professionals to decode data and offer actionable insights for better business outcomes.
The lifecycle of DS, encompassing various roles, tools, and processes, equips analysts to harvest these actionable insights.
The life and work of a data scientist: skills and tools
Data scientists are responsible for constructing and training prognostic models using data once it has been thoroughly cleansed. Following this, they articulate their analytical findings to key decision-makers, such as managers and executives.
Data scientists typically receive data that has already undergone initial cleaning and manipulation. Such preprocessed data forms the basis for advanced analytics programs, as well as ML and statistical analysis and methodologies, to further refine the data for use in predictive and prescriptive models. To construct these models, data scientists must delve into specific industry and business domains, harnessing vast amounts of data from various internal and external sources to address business requirements. This often includes data analysis to uncover concealed patterns.
Following their investigation, data scientists are tasked with presenting a coherent narrative to key stakeholders. Even this doesn’t mean an end to their work, for they must ensure the automation of their work so that insights can be delivered to business stakeholders on a regular basis, be it daily, monthly, or annually.
The clear need for collaboration between data scientists and data engineers to manage data and provide insights is evident. There’s an undeniable overlap in their skillsets, but, as the industry evolves, their roles are becoming increasingly distinct. While a data engineer deals with database systems, data APIs, and ETL/ELT tools, and is involved in data modeling and setting up data warehouse solutions, a data scientist utilizes their knowledge of statistics, mathematics, and machine learning to create predictive algorithms.
While the data scientist should have an understanding of distributed computing to access and analyze data processed by the data engineering team, their role also demands the ability to report to business stakeholders. Hence, they need a strong focus on storytelling and data visualization.
Data science’s impact and importance in modern industries
Gone are the days when business decisions were based on intuition. Today, a data scientist empowers decision-makers to sift through massive data volumes, identify patterns, and make informed, accurate decisions that boost profitability. In the modern business landscape, data science is not just a tool – it’s an absolute necessity.
Undoubtedly, data science has become a transformative force across various industries, profoundly impacting the way businesses operate and make decisions. Here’s how:
- Healthcare
By analyzing medical data such as patient records, clinical trial data, and medical imaging, physicians and researchers can predict health risks and develop innovative treatments. Imagine the ability to identify early signs of diseases like cancer, or predict susceptibility to illnesses like diabetes or heart disease, and implement preventive measures – that’s the power of data science. However, while healthcare research often presents inspiring and appealing concepts, the reality is that much of it remains at the research stage. The complexity of the subject matter, the myriad of edge cases, and the high stakes involved create hurdles for application in real-world scenarios.
- Finance
Financial institutions have benefited immensely from data science. By leveraging data analytics, they can discern consumer behavior patterns, manage risk more efficiently, detect fraud, and offer personalized services. From preventing loan defaults and credit card cancellations to improving investment decision-making, a data scientist can help banks streamline operations and reduce costs.
- Transportation
Analyzing data from various sources, including sensors, helps optimize operations, reduce costs, and improve safety. Data scientists can predict accident-prone areas, forecast public transit demand, and contribute to the development of AI in transportation, enhancing transportation efficiency and safety.
- Education
By analyzing student data, teachers can identify learning challenges and strategize interventions to improve outcomes. Data science helps build AI in education, predicting student success, offering personalized academic and career guidance, and informing teaching strategies and curriculum development.
These are just a few examples. Data science also plays a crucial role in marketing, HR, government sectors, and wherever data is generated. For instance, in addition to boosting accuracy in speech recognition tools like Cortana and Google Voice, it also helps marketers identify cross-selling and up-selling opportunities, HR professionals measure employee performance and predict attrition.
Data engineering: the backbone of data infrastructure
Data engineering encompasses the management of data, focusing on establishing systems that facilitate data collection and organization. It transforms unstructured, chaotic data into a coherent, structured format, enabling businesses to harness and exploit it effectively.
In a nutshell, data engineering is the cornerstone of comprehensive business process management. It underpins functions from finance and accounting to sales and customer support, all of which rely heavily on data.
By enabling businesses to distill vital information from massive datasets and base crucial decisions on thorough data analysis, data engineering has become indispensable. Consequently, the demand for data engineering services has surged in recent years, driven by the widespread adoption of big data.
The engineer’s role in data: responsibilities and skills
Data engineers are responsible for constructing and maintaining the systems that enable data science teams to access and interpret data. Their role primarily involves creating data models, building data pipelines, and managing ETL (extract, transform, load) or ELT (extract, load, transform) processes.
As developers and maintainers of data architectures, data engineers work with databases and large-scale processing systems. In contrast, data scientists put effort into determining how to clean, refine and organize data, a process sometimes referred to as “massaging” the data. This unique term highlights the stark differences in the tasks performed by data engineers and data scientists to make data usable.
Data engineers work with raw data containing errors from humans, machines, software development, or instruments. This data may be invalidated, include suspect records, and be unformatted or contain system-specific codes.
To enhance data reliability, efficiency, and quality, data engineers must recommend and even sometimes implement improvements. This involves using various languages and tools to integrate systems or identify opportunities to obtain new data from other sources, which can then be transformed into useful information for further processing by data scientists.
Crucially, data engineers must ensure that the existing architecture supports the needs of both data scientists and business stakeholders.
Finally, to provide the data scientists with the necessary resources, the data engineers must develop processes for data mining, modeling, and production.
Why data engineering is critical in today’s business landscape
Due to its critical role in facilitating data-driven decisions, data engineering has become an essential pillar in the modern business landscape. In an age where data is being generated at an unparalleled pace, robust systems and infrastructure are required to collect, store, process, and analyze these data, a task directly fulfilled by data engineers. They establish the essential infrastructure to manage immense volumes of data, thus ensuring its availability, reliability, and consistency. Moreover, they provide the following benefits:
- Enhanced Data Quality
Data engineers devise and manage effective data pipelines, allowing them to identify and rectify errors, inconsistencies, and duplications. This results in data that is accurate, complete, and consistent, enhancing the credibility of the business insights derived from it.
- Agile and Efficient Decision-making
The methodologies and processes in place enable swift and seamless access to relevant data, empowering organizations to make informed, real-time decisions. This promotes a more efficient operation, reduced response times, and improved customer service.
- Superior Scalability
Technical processes endow organizations with the capability to handle vast and complex data sets, crucial for businesses experiencing rapid growth or managing high volumes of data.
- Strengthened Security and Compliance
Data engineers work in close conjunction with organizations to ensure data protection and adherence to industry-specific regulations. This not only helps avoid costly fines and penalties but also strengthens customer trust and confidence in the organization.
- Deeper Insights and Analytics
By transforming raw data into a usable format, data engineers play a pivotal role in enabling businesses to gain valuable insights. This fosters a deeper understanding of customers, enhances marketing efforts, and promotes efficient product development.
Juxtaposing data engineering and data science: key differences
Data engineering and data science are pivotal components in the modern business landscape, often working hand-in-hand to drive strategic decision-making, optimize operations, and create competitive advantages. Data science turns data into insights, while data engineering provides the means to gather, store, and process that data effectively. Both roles are essential for businesses to leverage the full potential of their data.
Data science applies advanced statistical techniques, machine learning algorithms, and predictive models to extract valuable insights from raw data. This field is largely concerned with making data understandable and useful for decision-making. Data scientists help companies in the following ways:
- Predictive Analytics
By leveraging machine learning models, businesses can forecast future events like customer behaviors, market trends, and sales patterns, enabling proactive decision-making and strategy formulation.
Data-Driven Decision Making: Data Scientists convert complex data into actionable insights, helping leaders make informed, data-backed decisions. This can lead to more successful outcomes, from improving customer satisfaction to optimizing supply chain operations.
- Personalization
Businesses use data science to personalize customer experiences. By understanding customer behavior and preferences, companies can tailor their products, services, and marketing efforts to individual customer needs, thereby increasing customer loyalty and driving revenue growth.
Data engineering, on the other hand, focuses on the design and construction of scalable data pipelines, databases, and data processing systems that make large volumes of data manageable and ready for analysis. In a business context, data engineers support businesses by the following activities:
- Data Infrastructure
Data engineers build and maintain the infrastructure that houses a company’s data. This includes data warehouses and databases, which are crucial for storing and retrieving data efficiently.
- Data Collection and Transformation
Data engineers are responsible for gathering data from various sources, transforming it into a usable format, and ensuring its quality and accessibility.
- Scalability and Performance
As businesses grow, so do the volume, velocity, and variety of their data. Data engineers design systems that can scale to handle this growth, ensuring the performance of data systems does not degrade as data volumes increase.
- Data Security and Compliance
With increasing regulatory scrutiny of data usage and privacy, data engineers play a critical role in implementing data governance measures, protecting data from breaches, and ensuring compliance with regulations like GDPR or CCPA.
Comparing the Roles: Data Engineer vs Data Scientist
- A data engineer constructs and maintains the systems that allow for data access and interpretation, whereas a data scientist utilizes these systems to build and train predictive algorithms with the available data.
- A data engineer creates data models, develops data pipelines, and manages ETL/ELT processes to structure and clean data, whereas a data scientist applies advanced analytics, machine learning, and statistical methodologies to this preprocessed data for predictive modeling.
- A data engineer works with raw, unvalidated data containing errors and inconsistencies, even system-specific codes, whereas a data scientist works with cleansed, structured data, delving into industry-specific and business-related queries to address business needs.
- A data engineer uses various languages and tools to integrate systems or identify opportunities to extract new data from other systems, whereas a data scientist explores and investigates this data to uncover hidden patterns.
- A data engineer focuses on enhancing data reliability, efficiency, and quality, recommending and sometimes implementing improvements, whereas a data scientist presents their analytical findings in an easily understandable format to stakeholders.
- A data engineer ensures the existing data architecture supports the needs of data scientists and business stakeholders, whereas a data scientist, after their findings are accepted, automates the delivery of insights to business stakeholders on a regular, scheduled basis.
- A data engineer develops processes for data modeling, mining, and production, whereas a data scientist utilizes their knowledge of statistics, math, and machine learning to create predictive models.
- Lastly, a data engineer focuses on the technical aspects of data management, whereas a data scientist should also have an understanding of distributed computing, and their role further demands the ability to report to business stakeholders with a strong focus on storytelling and data visualization.
The collaboration between data science and data engineering: a vital connection
The collaboration between data scientists and data engineers is an essential connection for any business in today’s data-driven world.
This symbiotic relationship is akin to a well-oiled machine: data engineers create the infrastructure for data collection, storage, and extraction, ensuring its accessibility, reliability, and scalability. They build robust data pipelines and implement ETL/ELT processes to convert raw, unstructured data into a structured format that data scientists can readily use.
In complementary fashion, data scientists leverage their analytical skills to transform this data into actionable insights. They employ advanced statistical models and ML algorithms to identify patterns, trends, and correlations within the data. Together, the data team ensures that businesses can effectively harness their data’s potential, facilitating informed decision-making, strategic planning, and driving innovation.
Without this vital collaboration, businesses would find it challenging to navigate the vast seas of data and extract the valuable insights needed to stay competitive in the modern marketplace.