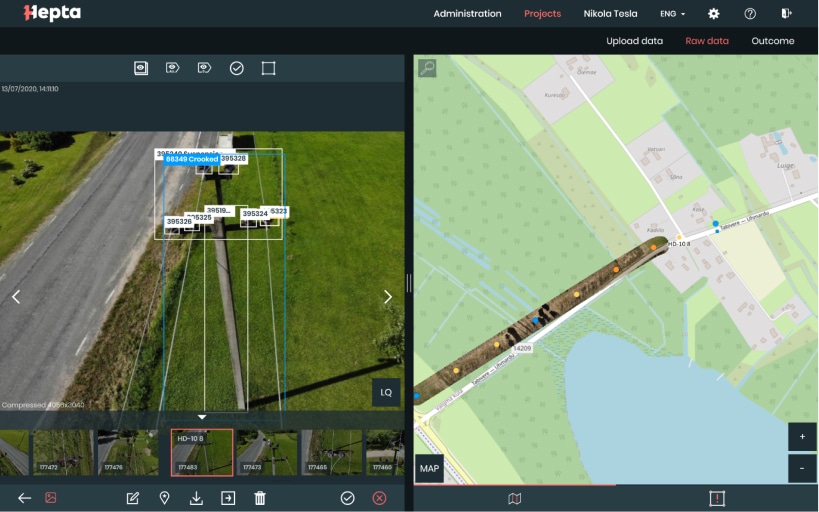
Hepta Airborne helps power line utilities to inspect their power grids with the help of drones to capture data and a specialized inspection platform called uBird to analyze it.
Their software produces a birds-eye view of the grid, its most critical parts and detailed reporting for work crews. Hepta’s solution helps power grid operators to have faster inspection cycles, detect more relevant defects and save on inspection costs. Today, Hepta Airborne is helping power grid operators succeed with their inspections on four continents and is actively expanding.
To increase the efficiency of processing pictures, the company decided to implement a computer vision solution and partnered with MindTitan in 2019.
Results of the case study
“The same amount of people could work on a greater amount of data. We didn’t fire anybody; we have actually hired more people, but it’s because of adding new clients and not because of inefficient effort.” (German Bidzilja, Head of Product)
The problem described: creating a highly accurate computer vision algorithm
Due to such different factors as weather, the power grid could be damaged. To fix any malfunction, the damaged place should first be detected. The previously common method of inspecting a power grid was for people to go on foot and take pictures, noting on paper the issues that they saw. It was inconvenient in terms of time, and the human factor could raise the inaccuracy rate.
To maintain power grids more quickly, drones, rather than people, take the pictures, but humans still have to check all the thousands of pictures, which is again time-consuming. The AI would enhance the process even further, reducing the number of images for human review.
German Bidzilja, Head of Product:
“The idea was to reduce the amount of manual work and increase efficiency.
We succeeded, although it took quite a long time to develop those ML models and experiment with technologies to find the best solution. Also, a lack of data delayed the process.
But, in the end, we tested the solution in day-to-day use and, finally, arrived at a decent model that was implemented into the product.”
Now, images are processed both by a human and with the help of artificial intelligence. Computer vision algorithms detect issues in the maintained equipment, enabling operators to fix them.
Creating the computer vision model
“We were looking for different solutions, so the expectation of AI technologies was and still is that we can process lots of images automatically without humans or at least with minimal human involvement. That would make the service cheaper.” (German Bidzilja, Head of Product)
To reach a high level of accuracy, the computer vision model should be well-trained on high-quality data. The ability of a computer vision algorithm to visually recognize a line defect comes from a sufficient amount of cases, well pictured and labeled.
Image recognition hurdles and solutions
As the field is peculiar, ready-made visual datasets for training artificial intelligence don’t exist, threatening the feasibility of this computer vision application. Consequently, Hepta Airborne (with MindTitan’s help) had to create its own dataset for AI image recognition training.
“We had to collect those datasets ourselves and have them in a good quality form for training the machine learning model. The lack of openly available datasets was definitely one of the challenges there.” (German Bidzilja, Head of Product)
Data collection faced several additional hurdles:
Hurdle 1: Uneven load distribution, making data processing time- and resource-consuming
The computer vision machine learning in Hepta’s case could not work in a live environment*, as the drone flies across vast areas with an Internet connection too poor for transferring the pictures from the drone while power and weight constraints limit on-device image processing. Each drone takes 200 high-resolution pictures per kilometer, bringing back to the base hundreds of gigabytes of pictures at once.
*A live environment is on the field at the transmission lines where the drones fly. These drones run on gasoline to increase the range so while it’s a rather off-road situation most of the time, it also covers a wide area in a single flight. Having a stable internet connection on the drone is not possible using the cellular network.
Markus Lippus, MindTitan Data Scientist Lead and co-founder, explained that most of the time, the AI had nothing to do, but, when the drones returned, an avalanche of pictures was uploaded, and you had to process them quickly. You don’t want to do it on-premise anyway, because it would mean you have a lot of hardware lying around that would cost you a lot of money but most of the time doing absolutely nothing.
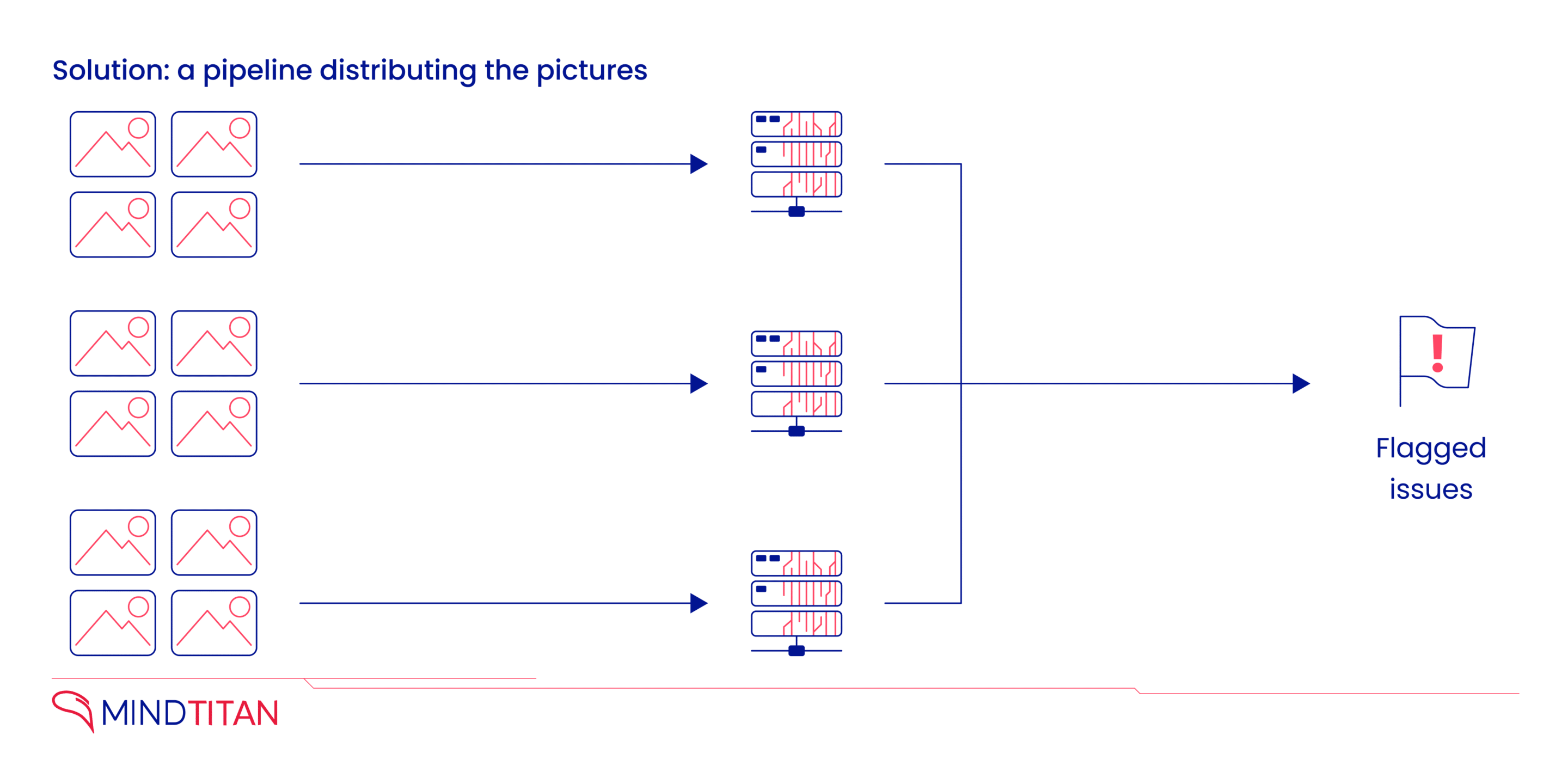
Solution: a pipeline distributing the avalanche of pictures
The MindTitan team had to set up the pipeline in the cloud so that the image upload triggered the data being partitioned into batches of reasonable size. Processing the batches was successfully parallelized, which means it became possible to scale up the computation power on demand and distribute the workload over a virtually unlimited number of machines
Split input into batches. Allocate X virtual machines and distribute the work. Collect the results in a centralized location.
Hurdle 2: Insufficient data detailing faults.
“We are working with tens of thousands when we’d rather have hundreds of thousands of images. Some issues are rare, and it depends on different countries as well. In some countries, the power grids are well maintained, and there are not many issues there, so it’s harder to find them.” (German Bidzilja, Head of Product)
On the power grid maintained with the help of Hepta Airborne, there are more than 30 types of insulators alone, each of which could have up to 15 types of rare faults, creating a huge variety of very specific categories to distinguish between.
The images of equipment faults were so varied and the details required for detection were so small on the images that collecting enough data about every fault case for the proper machine learning process appeared to be impossible.
Solution: data augmentation
The MindTitan team had to implement data augmentation. The solution was to transform existing data to look more varied, so the machine wouldn’t paint itself into a corner, being able to detect only the specific angles of the faults it had seen before. As the computer vision system has to recognize the fault from all angles, the data was artificially multiplied at least 10 times.
Hurdle 3: Labeling had to be very precise.
Also, the company had to balance money expenditures and data quality.
It is vital that the ML algorithm not learn from contaminated data: if an image is fed into a system, then every element on the image should be labeled.
It is no use labeling just the faulty element, as the machine, learning from unlabeled parts as well, could deliver the wrong results.
Thus, if there are 100 elements in the picture, and one of them is faulty and necessary to detect, then all the elements should be labeled not to contaminate the process of machine learning.
Solution: perfect labeling
German Bidzilja said, that the team tried to find data labeling companies from all parts of the world, where you should have that service cheap and fast. Unexpectedly, MindTitan found the most efficient way appeared to be to contract a team in Estonia who labeled the data perfectly. “It was a didactic point that not always Indian companies can compete in price and efficiency,” he added.
AI models described
“We use object detection. It highlights this component of the image and classifies whether it needs maintenance. It finds the object and says if this insulator is broken or chipped and so on. The model that MindTitan developed was identifying these issues, we know that there are many more defects, but decided to concentrate on this model first for insulator issue detection.” (German Bidzilja, Head of product)
For Hepta Airborne’s goals, MindTitan developed a custom machine learning solution. First, the machine learning model processes the input data brought by drones and produces an output based on it.
If the machine suspects a faulty detail, the system flags the image and the human specialist reviews the case, providing specialist feedback and a decision.
By adding the reviewed cases to the training examples afterward, data scientists improve machine learning algorithms; consequently, the machine becomes more efficient over time with more complicated examples. In theory, it might be possible to reach full automation with this machine learning process. However, the field of power grid maintenance is so complex that new edge cases requiring human revision keep popping up, and the goal of 80-90% accuracy of automated decisions is still there to hit.
“MindTitan was flexible and followed our use case peculiarities. When we synced up on what we wanted to achieve, the MindTitan team was like-minded regarding our case and provided insightful ideas and improvements to our processes. Thus, as our partners, they were exceptionally involved and had a deep understanding of our needs. It’s good to work with experts in the field, and the MindTitnan Team knew what they’re doing and made good suggestions. It was so nice to work with experts.” (German Bidzilja, Head of product)
AI training process
As mentioned above, the computer vision model should be well-trained on high-quality data, at this point a new hurdle appeared.
Hurdle 4: a lot of data and a lot of ML iterations
As the model has to work on high-res data and work on different scales, this made the model fairly complex, and while using normal resources, its training could not be expected in a reasonable amount of time.
Solution: Using high-performance computing.
When the AI training became quite unwieldy, at that point, the MindTitan team suggested doing distributed learning, extending it to the cloud, and using its high-performance computing (HPC) capabilities to reduce training time from expected months to a week in reality.
The machine was initially trained on consistent images (made from 3 angles, exact distance), but when randomly made images came into the process, the accuracy of the system dropped immensely. Machines are trained for specific cases, if one puts different data into the process, then it wouldn’t work properly, for example, it still could recognize the objects but couldn’t detect the faults.
“We had to experiment. Luckily, MindTitan supported us with several ideas to try, including how to better gather data. We had our own in-house team and we put our efforts together to understand what kind of data is usable, which ways are there to label it correctly, and so on. MindTitan guided and helped to support data collection for this project.” (German Bidzilja, Head of product)
Conclusion
The AI implementation allowed to process more pictures with the same team, speeding up the procedure by 15%, and the detection became more accurate as the computer vision system allows finding on average 11 more defects per line kilometer. Also, the machine learning algorithms helped optimize the time and money expenditures and led to business profit.
German Bidzilja, Head of product explained that the fact that the work can be done faster, makes it cheaper. It’s faster, but the underlying goal is to have a cheaper service. “Imagine the difference between going over thousands of images, or over 20 or 30 images,” he added. However, Hepta Airborne reached its first results with the help of MindTitan.
What was the main benefit of working with MindTitan? It’s kind of the same as having the in-house team.
German Bidzilja
, Head of product
“It’s just that working with MindTitan helped us to kick-start the AI development faster, we had experts, and created the data and the models much faster than if we would get new people in the team, training them on our use case.”
Hepta Airborne now continues working on the AI project, developing the computer vision system and setting up the ambitious goal to hit 80-90% accuracy of automated decisions, thus almost fully automating the process of faults detection on power grids, enabling operators to fix them, and ensuring that people have a more stable power supply.