Business leaders, considering AI implementation, face the need to plan the process strategically. To succeed with it, it is vital to know the stages that AI projects go through while evolving and maturing. Unfortunately, existing models of AI life cycle (ex., CRISP, or CDAC AI life cycle) are not perfect: either too generalized, too technically overloaded, or concentrated only on the AI development part, whereas the entire process of AI implementation and solving real business issues with it is much broader.
Thus, MindTitan’s AI scientists and experts suggest the comprehensive life cycle of AI, that is easy to grasp for businesspeople and use in their work. Providing custom AI solutions and having accumulated experience in setting up machine learning (ML) and artificial intelligence (AI) systems for more than 80 projects in 20 countries worldwide, MindTitan describes the AI life cycle from an idea to production in this article.
The stages below indicate the maturity of the project, which are crucial to know before deciding what financial and human resources to allocate.
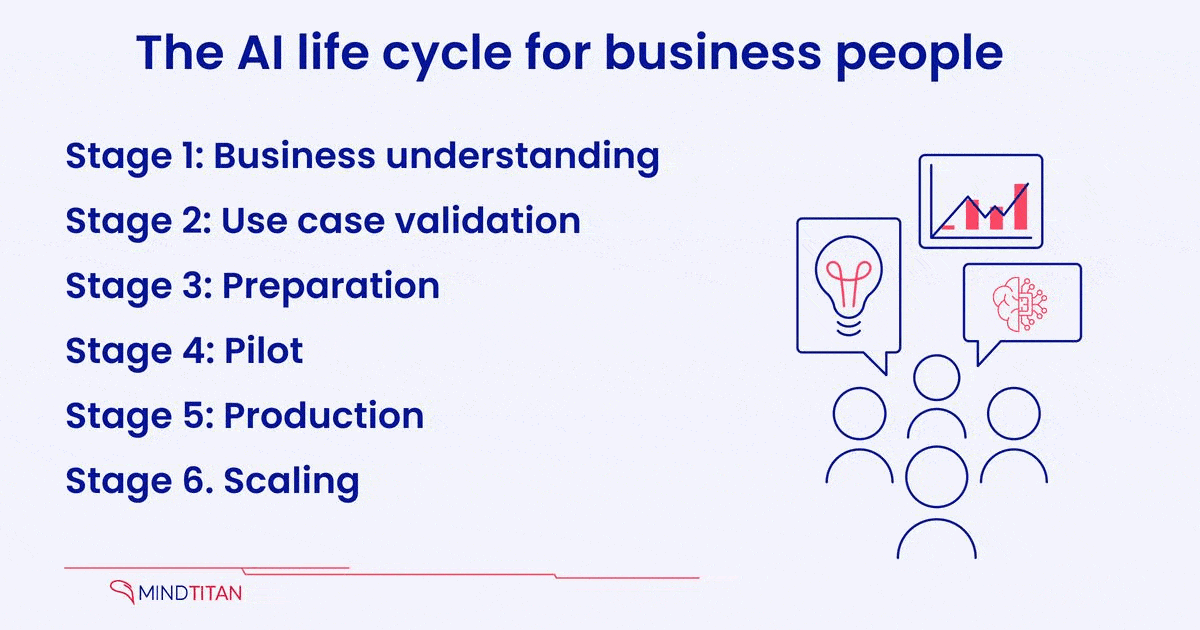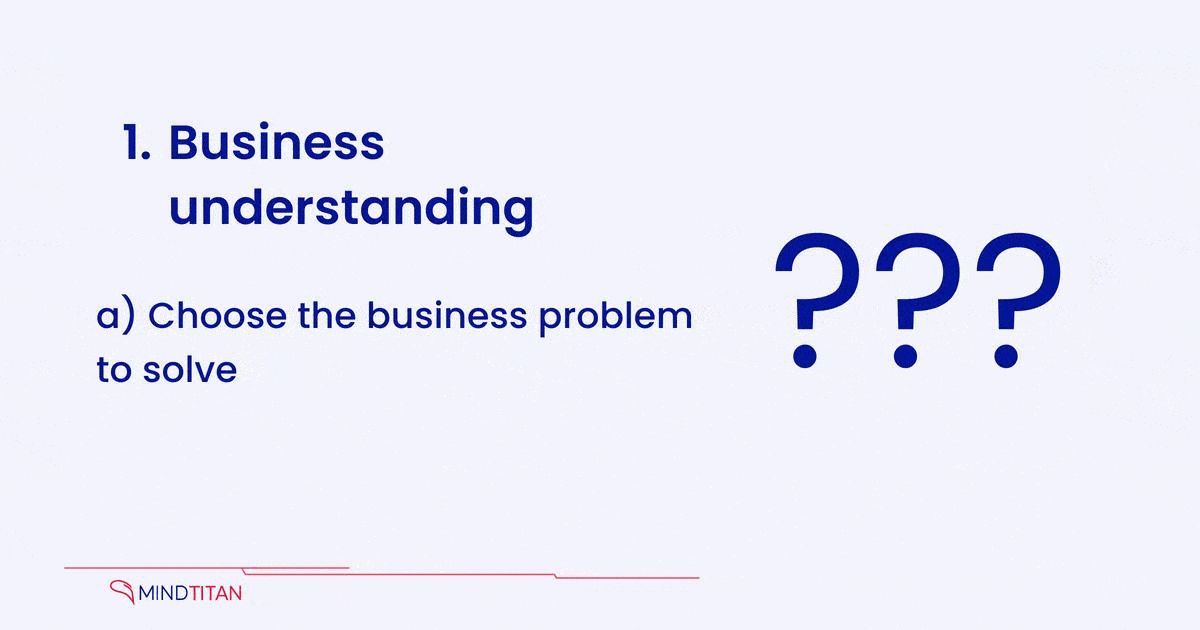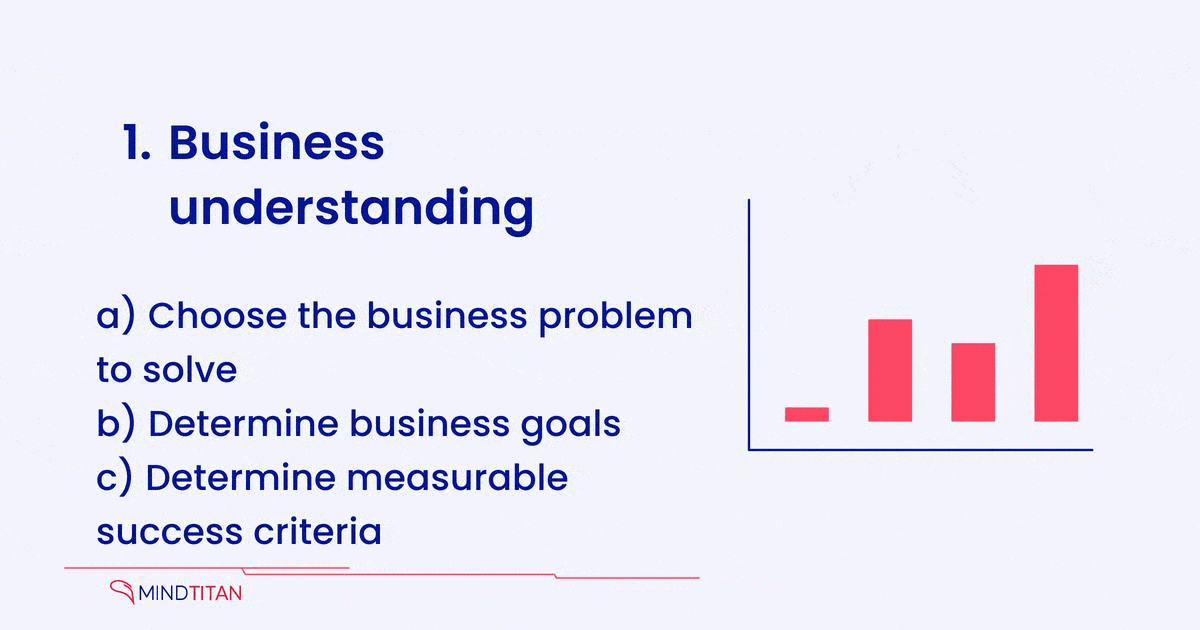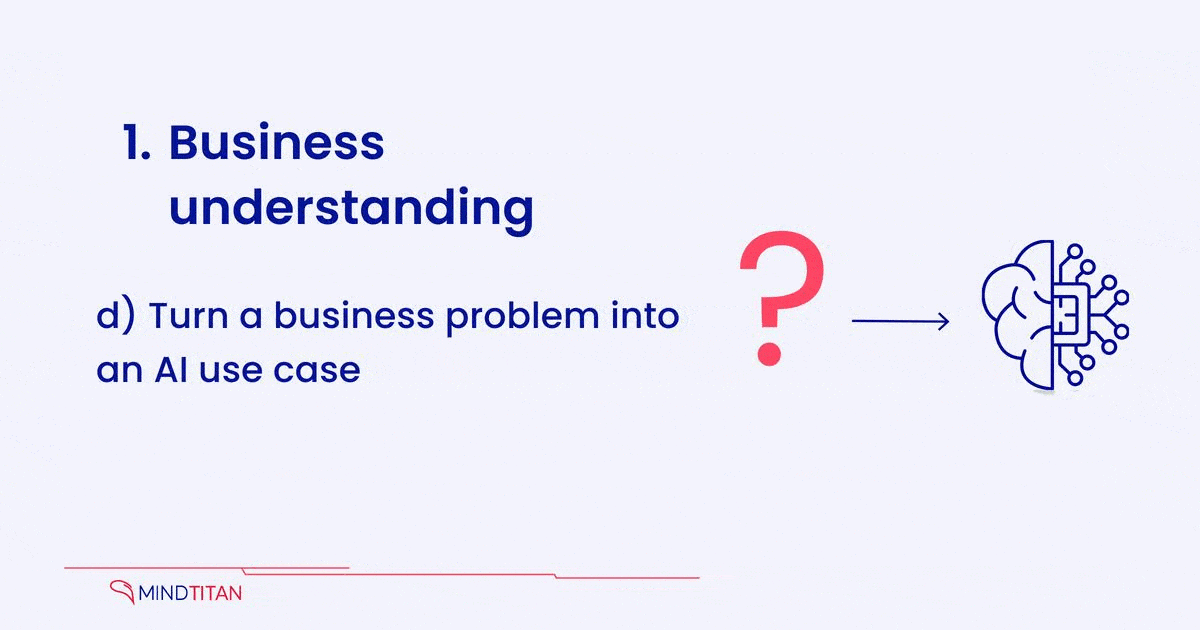
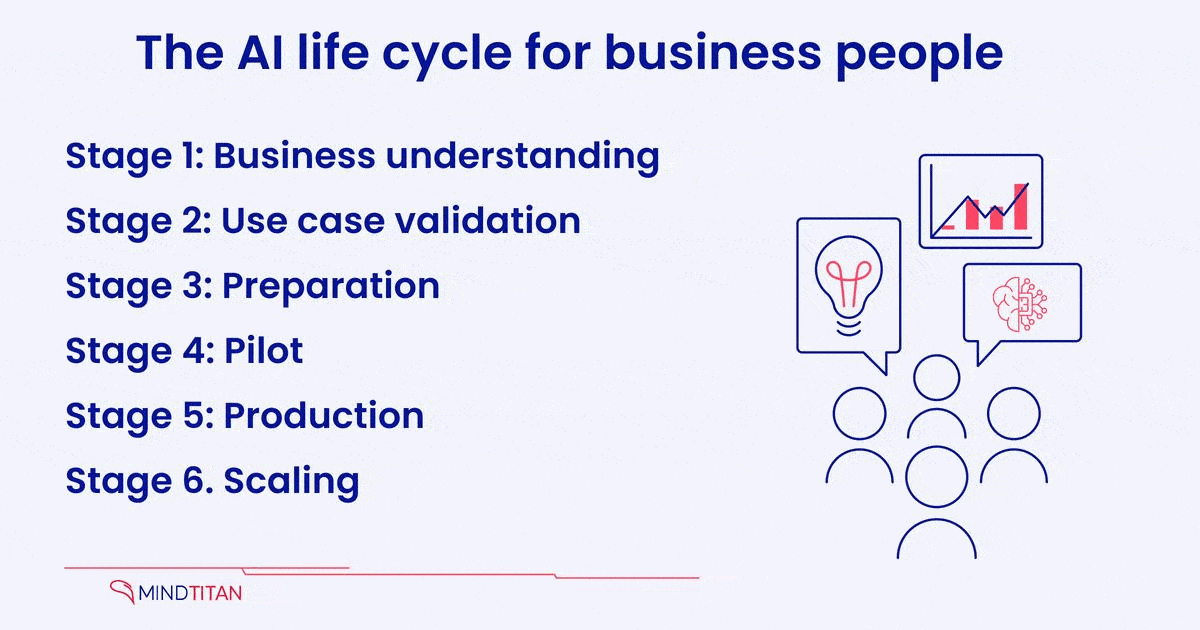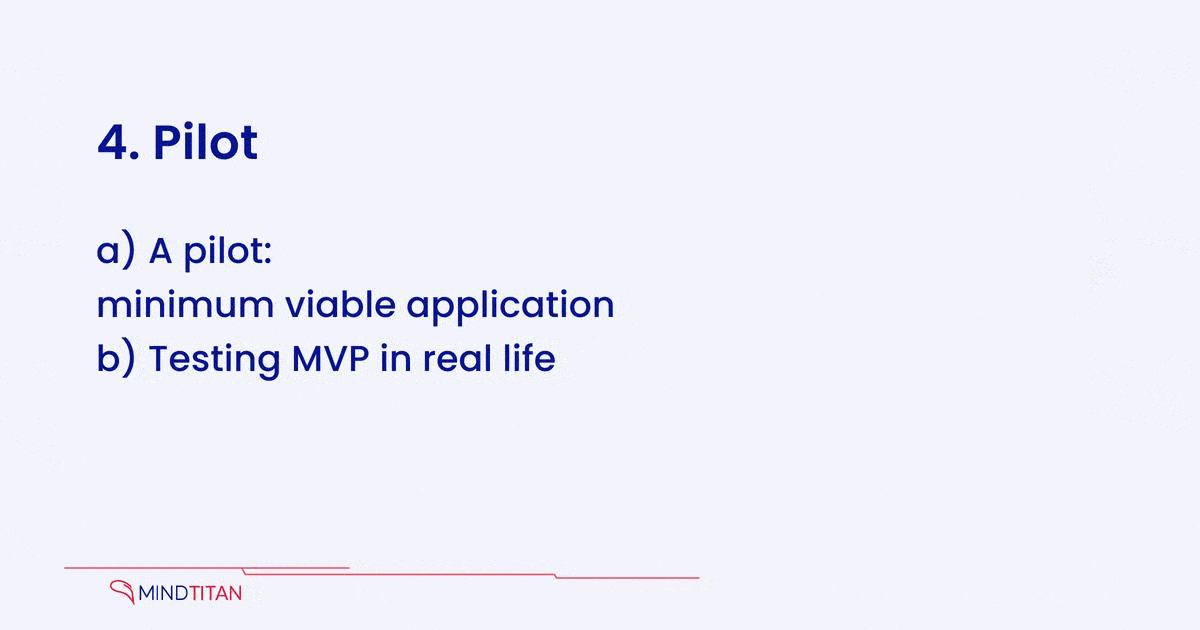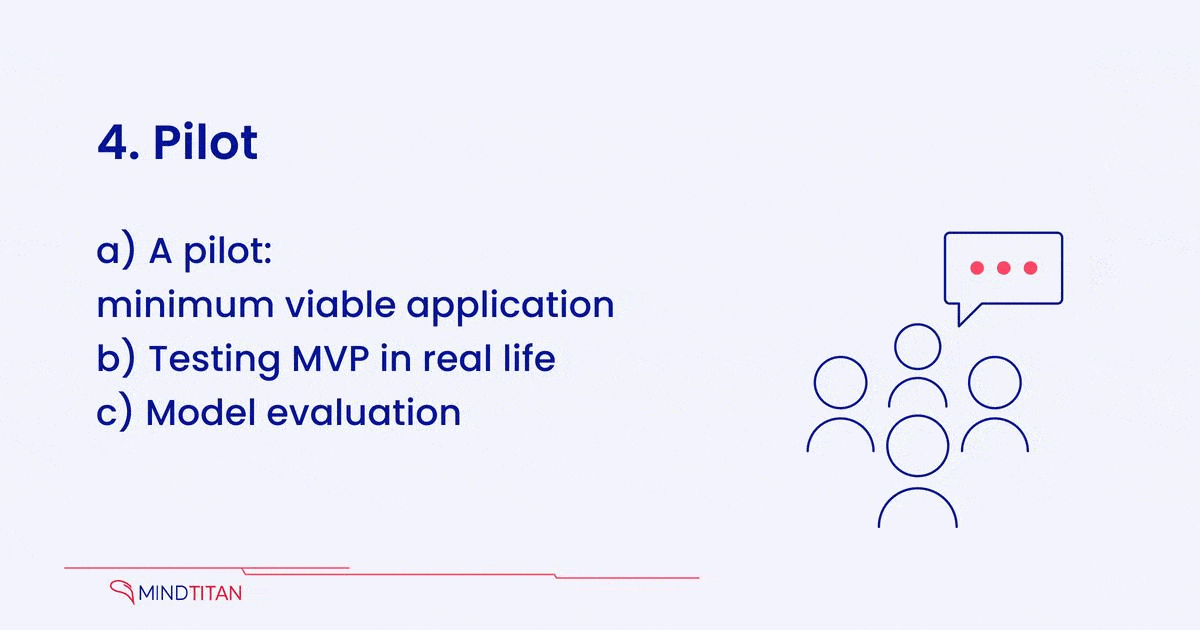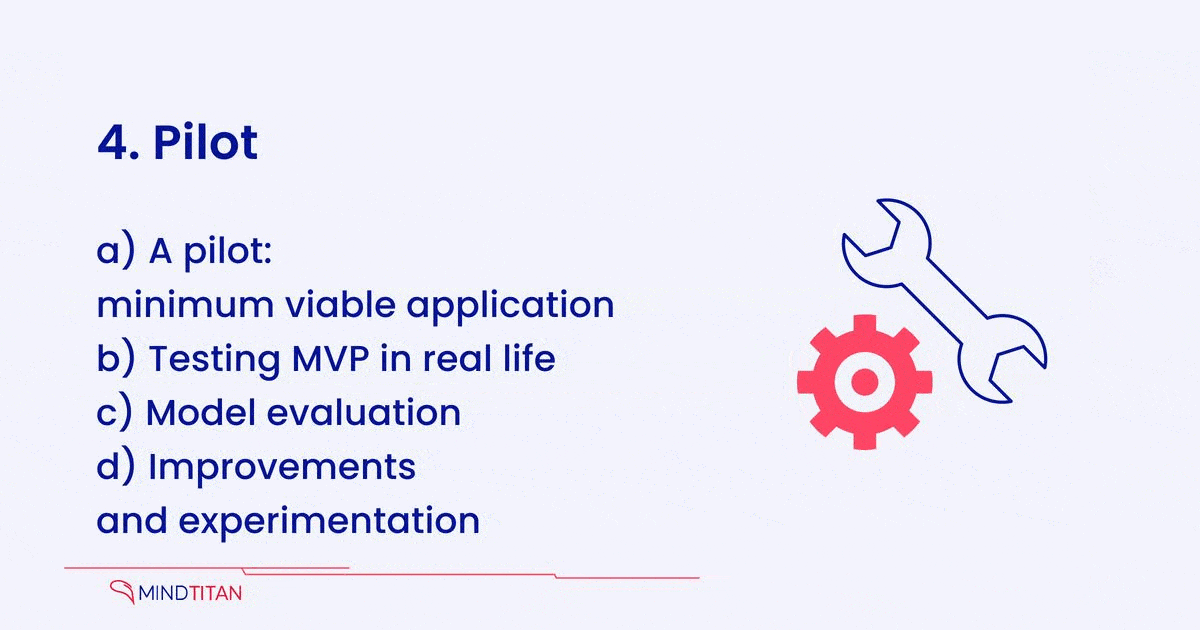
To clarify, let’s find out the AI implementation process’s core meaning and feature actions. In our version, the business understanding stage is followed by idea validation, preparation, pilot, production, and scaling.
The first two steps (although they are the ones with the smallest budget) are vital for moving the project in the right direction. You cannot expect good final results if these steps are not done well.
However, the business-thinking effort decreases over time while being very high initially. Thus, we pay much attention to stages 1 and 2, uncovering the details that will lead the AI project to success.
Nevertheless, the efforts of the businesspeople are not to disappear at later stages: their involvement in the assessment of the intermediate results will be meaningful.
A technical team of the AI project, contrarily, will invest more and more effort over time.
So, various specialists must contribute more effort throughout different project stages to deliver a high success rate.
1. Business understanding
First, it is essential to define a business issue to solve and then the exact process to enhance. Having a lot of data, it could be tempting to try to look through it first for use. However, avoid starting with the data. Instead, explore the problems first by talking to your specialists, knowing the processes from A to Z, even though your business could have massive historical data.
a) Choose the business issue to solve
There is no only way to understand which issue is a good fit for AI implementation. However, you can figure it out your way, using many guiding questions to help the business and AI experts decide which problems and processes are the best candidates to solve with artificial intelligence.
The key is the people who know your company’s different sides and operations at best and can bring out the issues with the most significant impact. Ask these people to define, as precisely as possible, some problems they need to solve.
Additionally, ask your specialists two primary questions to determine if the AI implementation is feasible for the process.
Could a person do it quickly (in seconds)?
Could you see a pattern if it would fit into Excel?
Only having positive answers means that you may choose those issues to be solved with artificial intelligence. Then, assure that you provide the needed access and support to the AI team while conducting initial research on the current processes and the data and formulating a hypothesis.
Signs that the challenge could be solved with AI
Please, check out if your idea of improvement meets the following criteria:
Selecting the tasks and processes to be automated with AI, consider that process to be automated should be mostly routine and standard. Although it could be complex and its sequence could be extended, if it is a routine, without often popping-up edge cases, it could be a task for artificial intelligence.
Another essential feature is the possibility of creating a learning loop. There are many versions of it. Still, they all allow the AI model to improve constantly by continuously updating and processing training data of better quality. In the picture below, you can see one of the learning loop versions, human-in-the-loop. A human, for example, an auditor, checking the social media posts for illegal political advertisements, gets the input from artificial intelligence, flagging the frequent appearance of exact politicians. Then the human confirms or rejects the cases and deals with the most complex ones, sending their decisions as feedback to the AI model. Thus, AI algorithms learn on better and more complex and fresh data, and the entire AI solution can provide more accurate results.
Additionally, working together with AI models, sensors rarely give us an excellent picture. Even with the current technological advancements, handling those tasks with complex and vast interactions with the physical world isn’t easy. But, of course, if the returns are high enough, it is worth doing. For instance, many companies are developing self-driving cars, but the difficulty in solving these tasks is immense.
To sum up, the best variants of the process for AI implementation are ones that have the following features:
Processes that are mostly routine and standard
Processes where it is possible to create a learning loop
Processes where interactions with the physical world are nonexistent or simple
Another dimension of figuring out the process to enhance with AI is to think of it in terms of resources: working power and time.
For example, the processes requiring a lot of people are often relatively easy and probably produce a lot of data. If such a process repeats often, AI automation, even semi-automation, could benefit significantly.
Some processes require considerable time for analysis before making a decision. For instance, let’s get back to the auditor’s example. Usually, they have a vast amount of information (in our case, social media posts) to manage. Thus, they look at the most critical or disturbing cases to come to a decision, which mainly works fine, but there is room for improvement. AI quickly looks through all the data and can help the auditor highlight where more attention is needed. Thus, the auditor can provide more high-quality decisions.
The same applies to the processes that include an immense amount of factors and connections between the data collected. For example, predicting traffic accidents or forecasting the best position for a police patrol requires a lot of data and links between them to be processed, which is impossible for a human to grasp. However, for well-trained AI, it could be a piece of cake.
Considering AI solutions, take a closer look at the processes, meeting the following descriptions:
Processes that are performed often and that require a lot of people
Processes that could be done better if there was more time for analysis before decision-making
Processes that could be done better if we could see all the connections between the data
b) Determine the business goals
At this point, it is important to define as precisely as possible the exact result you want to deliver to your end-users/customers from the business perspective. For example, considering conversational AI, it would be helpful to think of the channel your customers use.
c) Determine business success criteria
To make the goals clear, the definition of the exact measurable level of enhancement you want to reach with AI implementation will be convenient. For example, reducing the clients’ waiting time on the phone from 3 minutes to 30 seconds after conversational AI implementation or speeding up defect detection (and thus reducing or eliminating downtime at all) on the pipes or power grids to 15% due to using AI for utilities.
d) Turn the business issue into an AI use case
The first step of every AI project is to understand if the idea presented is a problem to be solved with artificial intelligence. Complete understanding of the current situation and necessary changes to the process, data, application, and infrastructure require discussions with both the business and technical sides is vital. Additionally, those meetings will help to outline very rough time and budget, understand business value from potential returns, estimate the difficulty from an AI perspective and make an initial plan for the further steps.
Gap analysis and machine learning canvas will help to put the entire picture together; thus, we created a guide on how to fill it correctly.
Here are several examples of the questions to answer:
How is the issue currently solved?
What is the flow of the process (steps/phases)?
What data is collected, how is it stored, and what data is available?
In addition to the business questions above, the tools (ML canvas and AI GAP analysis) also touch on the issue’s infrastructure, application, and data side.
The outcome of the first stage of the AI life cycle:
One or more business concerns have been turned into an AI use case, for example, by using a machine learning canvas.
2. Use case validation
After the first stage, you already have defined AI use case(s). The second step is validation. However, the use case description could still be specified further during this stage. At the end of the validation stage, if the amount of relevant data allows, the quick building of an initial AI model might be possible. It will help to clarify if there is a promising signal in the data that can significantly decrease the uncertainties of the project.
a) Validation with business and technical stakeholders, as well as with data science lead
At this stage, it is essential to assess all the sides of the idea, make sure that everyone understands it the same way, discuss concerns, and remove blockers. You have four main questions to discuss, and after getting positive answers for the first one, you can move to the next one and further. In the end, you have to get three positive answers and one “maybe” (we will explain that fourth one below).
First, Could the process be automated?
On a business side, together with person/people deeply knowing the process to automate, discuss the map of the process, its’ exact steps, as well as input and output, the desired outcome, and criteria for AI success. Then, discuss with the AI solution team what part of the process can be automated (whether it’s a complete process or just a part) and whether it makes sense. For example, processes with many edge cases may not be suitable for automation.
Second, Should the process be automated?
What is the business issue you want to solve using AI automation? Are you looking for automation gains, or are you not simply performing the task well enough, thinking AI could help? For example, if the result is 0.5 full-time employees work automated, automation might not be worth it.
Once you know that the process could and should be automated, you need to consider your options.
Third, Should you use AI to automate the process?
You already have defined business success criteria and what would be the level making the business more efficient than it is now. Ask AI experts to verify whether it might be achievable (some things could even be tested out with a proof of concept). Then, using verified measurements of success and business knowledge, you have to figure out a way to calculate ROI – there’s more than one way of doing this, and you might need to be creative.
Last but not least question to answer at this point: are there any alternatives? The best way to find it out is to talk to AI experts and other technical or process experts. It might be necessary either simply to restructure the process, make some other technological changes, or, of course, to leverage the AI option as well. However, if it is possible to reach the desired results with less complex tools, better use them. Even though some already relatively cheap out-off-the-shelf AI systems exist, most effective custom AI solutions require a significant investment.
Fourth, Can you use AI to automate the process?
This question is to validate with the AI solution team. AI models require a significant amount of data with reasonably good quality. Thus, it might be necessary to work on the data to bring it to the AI models’ demands. Furthermore, to continuously improve, artificial intelligence will need a learning loop; therefore, it might be necessary to restructure business processes to create that learning loop. Of course, you have to consider the investments in doing this, but fixing the situation with your data and creating a learning loop is something you should consider as part of your AI project. However, a definitive yes/no might not yet be possible, and “maybe” is the best answer at this moment because sometimes you simply have to test.
Moreover, an uncertain answer to the question “Can you use AI for automation?” does not mean that the AI model leveraging is immediately impossible. Usually, there is a way to improve the starting positions of data quantity and quality and process enhancement.
Nevertheless, there are obvious no-s as well from data scientists: if the problem is not suitable for AI, it would take too much time/money to solve it with the AI, and/or the chances of it succeeding are extremely low, although not zero.
b) Initial Proof of Concept (PoC), if possible
Proof of Concept is a digital product’s minimal working state, or at least a particular working part. A PoC demonstrates the feasibility of your business enhancement idea, or in other words, answering the question, “Can you use AI to automate the process?”. Sometimes from the start, there is enough data with good enough quality (good enough doesn’t mean that it shouldn’t be possibly improved), and it is logical to test if there is any signal in the data.
A proof of concept clearly presents AI capabilities using actual data for output to solve your real business issue. Furthermore, it clearly shows whether a use case could provide benefits from that specific application. In other words, it defines whether an AI solution will succeed. In the previous steps, you already have identified the process to enhance and validate this AI use case is realistic. Now developing a PoC AI solution team can deliver and compare different AI models and approaches. At the same time, the business side team can assess the value of the AI implementation and analyze the process itself: whether it should be replicated or changed in some ways.
However, the data is usually not yet there at this stage, and it is not possible. Nevertheless, minimal work should be done to define what a successful PoC would look like in the next step.
The outcome of the second stage of the AI life cycle:
A green light (or at least not bright red, if an AI automation possibility is uncertain) from the validation questions and a plan for preparatory work for the next stage.
3. Preparation
The third step is preparations for building a proof of concept, building and verifying the PoC, and preparing for the pilot after that. The current situation determines how complex this stage will be: it could start from collecting and labeling the data before the development of an actual PoC is possible. There are three types of PoC:
Technology PoC: It means developing just the model and dataset needed for training and evaluation. If the PoC model doesn’t work well enough or doesn’t suit the business goals, then it makes no sense to develop a tool around this.
Process PoC: AI can introduce a new business process flow. It is vital when you are unsure whether clients or employees will use the tool and follow a new approach you develop. To test a tool/process and see how it fits with internal or external users means to mock the process (with people playing the AI in the background) as if the AI already exists.
Assuming PoC technology development shows positive signs, it makes sense to set up proper deployment logic so that future iterations would happen quicker. Additionally, create data pipelines so that the PoC could run on live data if that is necessary for the data science project.
Thus, from the technical side, providing proper data access for the AI solution team is vital. Data dumps are okay initially, but once there are good enough signs, one should consider connecting them with the actual data sources to increase the iteration speeds, as messing with different data dumps can become a burden.
a) Data collection, preparation, and labeling
Machine learning models should solve a given problem based on the data. Usually, businesses might already have data for AI to train on. Thus, it is better to start with it. However, if it is still not enough, existing data could be used to verify the necessary quality to create guidelines for further data collection.
Often, the issue isn’t that the organization does not have any data. Still, the business might use it for other purposes. Thus the quality and/or structure may not be good enough. For example, data quality might be acceptable to look at trends because the mistakes become average over time.
Nevertheless, these data might not be suitable for AI training to make predictions as there might be too much noise in the data. It might be possible to clean up the data enough for AI. But sometimes, the data cleaning could be so hard that it’s easier to collect new data.
Data quality, quantity, and balance are the decisive points in data collection. The more training data we have and the better the quality and balancing are, the better the model will learn and predict accurately, and the more trustworthy AI will become.
First, an initial data acquisition is needed, then the process continues with activities to get familiar with the data, identify data quality issues, discover first insights into the data or detect interesting subsets to form hypotheses.
The quality of the samples is important because wrong or misleading samples (called noisy data) or metadata with questionable usefulness will confuse the model and drastically plunge the prediction quality. The data quality is improved with data cleaning, which means cleaning the data by identifying noise, false or misleading data, and correcting or removing it from the training set.
Then the data should be labeled: in machine learning, to put it simply, data labeling is the way to explain to the machine what it should learn from the data. Every datum, whether it is an image, text file, digit, or video, gets one or more meaningful and informative labels so that an ML model can learn from it. Labels might say, for instance, if a photograph shows a bird or an automobile, which words were spoken in an audio recording, or whether a tumor is visible on an x-ray. Data labeling is required for various use cases, including computer vision, natural language processing, and speech recognition. At this stage, it is vital to help the AI team annotate the data. Ideally, a person from the business side, knowing the improving process well, shall join the labeling process or at least supervise it and provide feedback.
b) Data pipelines
A data pipeline defines the mechanism that determines the flow of relevant data from its origin to its destination, including the various processes or transformations the data might undergo along the way. A standard pipeline is quite like one of the most basic computing processes of Input → Processing → Output.
c) Proof of concept development
Proof of concept (PoC) is a general approach that involves testing a particular assumption to obtain confirmation that the idea is feasible, viable, and applicable in practice. In other words, it shows whether the software product or its separate function is suitable for solving a particular business challenge. Later it will turn into a prototype, afterward into the minimum viable application (MVP).
Data exploration and preparation are the keys to AI solutions; thus, this part of the AI life cycle has vital meaning.
d) Proof of concept results and their assessment
Analyzing PoC performance, we can provide clarified answers for the four main questions to AI validation (you can see them in the picture below), but there are still uncertainties that you should be aware of and accept as a usual way of AI creation. As the project evolves, you learn a lot about the usability of the technology.
Exact objectives may change as you find it’s not good enough. For example, if you try object tracking on images, the actual classification could not be good enough. However, just localizing areas of interest, in general, could be already helpful.
New use cases for the same technology could appear. For instance, Elisa implemented call automation, but on the way, found out it is an effective tool for collecting technical error reports.
However, this step helps define the exact MVP (or pilot) we are building in the next step. Also, it is essential to answer the following questions:
What is the scope?
Who will be the users/alpha testers?
Who will do what if it is a joint project between multiple teams?
What is going to be the timeline and budget?
What would a successful MVP look like in the next step?
This work should be done in iterations; thus, you have checkpoints to decide if you keep on going this way or change direction. If everything goes well, it’s time to make a pilot plan.
The outcome of the third stage of the AI project cycle:
The idea is validated as well as it can be at the moment, but more testing is required.
The pilot plan includes not just an initial (PoC) AI model but a minimum viable application of the tool that people can use.
4. Pilot
A pilot or a minimum viable product (MVP) is an initial model representing a version of a product with just enough features to be usable by early customers. Those users then can provide valuable feedback for future product development. Eric Ries, who popularized the term, defined an MVP as that version of a new product that enables a team to get the most verified learning about clients with the least amount of work.
a) A pilot: minimum viable application
Building only the AI model is often not enough; MVP around it assures that end-users can take advantage of the AI model output and gather feedback live. This is the stage where the feasibility needs to be fully proven for full-version production.
MVP allows the following:
Test a product hypothesis with minimal resources
Accelerate learning
Reduce wasted engineering hours
Get the product to early customers as soon as possible
b) Testing MVP in real life
Testing is the essence of the pilot stage and the requirement for gradual, market-tested expansion models. As described above, an MVP seeks to test out whether an idea works in market environments while using the least possible expenditure, thus determining whether the product should be constructed. Real-life testing determines whether the initial issue or objective is resolved in a way that makes it appropriate to proceed. Although it is done with a limited alpha/beta version, it leads to a mature AI model, thus more business efficiency.
The AI model improvements happen based on feedback, as well as running different experiments to ensure we have the optimal solution and not missed edge cases, which would be beneficial in the end. It reduces the risk of innovating, so those enormous investments would not have to be sacrificed before proving that the concept does not work.
c) Model evaluation
The metrics have already been clearly defined before. Still, now those metrics should be getting proper testing if they work and deliver business value. It doesn’t mean that they might not have to be modified later, but at least it should be clear if the metrics don’t make sense.
For example, It is one thing to have good metrics for speech-to-text and text-to-speech models and another to see how people react to (semi-)automated calls. This needs to be tested at least on a subset of customers.
The result of this stage should be an understanding how what the complete system would look like and how it should be improved compared to the MVP. If the required changes are drastic, there might be a need to build another MVP first and test it again before proceeding to the next stage.
d) Improvements and experimentation
Some flaws will come up during the testing in real life. Consider it as the first one of endless iterations of improvement on the way toward mature AI.
The AI life cycle is data-driven because the model and training output are connected with the training data.
Rule of Thumb: Start Small, Learn Fast
Machine learning projects always involve a high degree of uncertainty in terms of workload and result quality. Therefore, to minimize the risk and investment as well as for end-users, it’s better to strictly follow the “start small, learn fast” AI project management philosophy.
This means building a feature-complete system with the minimal possible workload to get fast feedback if the model and available data play well together.
Compare the efforts to develop the proof of concept with its results, consult with ML experts, and they will help you to understand when you are ready to go into full development.
The outcome of the fourth stage of the AI life cycle:
The minimum viable application tested in real life and verified its value for the business.
Assessment of the MVP and planned fully functioning system differences: how much the application and the AI model should be improved to go into the next stage. If the changes are profound, it is better to go back to building another MVP.
5. Production
At this stage, everything is developed into a ready-to-go state, and real users can work with it. To achieve it, machine learning processes called MLOps (kind of like DevOps for ML) are set up, thus developing the complete application where the AI model can be exploited. Good experts won’t forget to develop a proper reporting system to understand the outcomes and monitor the situations to ensure everything is running as expected. Of course, the AI model (as well as AI capabilities) will improve as well as any other IT system if well maintained over time.
a) Full application development
When the pilot stage is done successfully, it is time for full application development. It means that all functions planned at the first stage become live – with the help of machine learning operations (MLOps).
Here the ML team makes the algorithm that learns from the data and improves its results during the time (given that the data is correct and clean)
With a set of engineering practices specific to ML projects, data scientists and ML engineers take machine learning models to production. These pipelines’ outcome means higher software quality, faster patching and releases, and higher customer satisfaction. However, this step requires a deep understanding of technical details; thus, the best option is to delegate it to experts.
b) Monitor and assess, maintain and improve. Repeat.
As mentioned above, the AI project is constantly evolving: data, data sources, customer behavior, or other things could change; thus, the model should be adapted. It is crucial to keep in mind that the AI model development process and training are iterative. New data comes after initial implementation, which leads to a new training cycle and sometimes even new business goals. For example, as a call center automation project matures, a KPI could change from pure automation to higher satisfaction. That’s why the contact between the business and technical parts of the AI project team should be continually maintained.
It is vital to monitor and evaluate the performance of the AI model not only from a technical perspective (such as accuracy fluctuation, changing data or environment) but also from a business perspective (such as end-user reactions, ROI from reduced costs, increased revenue, or improved process)
Working closely with business people, a machine learning team will identify the key areas where AI can bring the most value. Then they develop a roadmap for action and implement AI successfully, delivering the most benefit to the business.
The outcome of the fifth stage of the AI project cycle:
Ready full functioning AI system built-in application.
Established and iteratively working cycle of actions to further AI learning.
6. Scaling
Not all, but many models might require an additional production level to make them fully scalable. As nearly no downtime is allowed, it needs to be able to function under a massive load.
Another side of scalability is a rollout, for example, to all call centers, all factories, all client segments, or any other kind of scaling. To meet these expectations, pay attention to the AI solutions’ high availability, load balancing, and fault tolerance.
Scaling an AI project is not a natural or fast process. In general, succeeding in this step will take time.
The outcome of the sixth stage of the AI life cycle:
Scaled AI project, providing notable benefits and business value.
Conclusion
Business leaders, Implementing AI, can wisely invest in business development, knowing which projects are mature enough to generate ROI very shortly; where processes might need to be adjusted to bring them into everyday use; which projects are in early stages with much uncertainty, et cetera.
Now, you have a framework to understand the complete artificial intelligence life cycle from a business perspective. It enables an understanding of the AI project’s maturity, what kind of output should be expected from each stage, and the logical steps/team requirement needed at each phase. But, of course, real life might not be as straightforward as a written plan, and there can be back-and-forth between different stages. Thus, it is crucial to have machine learning experts around to share their experiences and support your business on the way to successful AI implementation.